
Architectural Quality Attributes
I. Usability
This is the definition of the usability attributes that are required from the business. This addresses the complexity/simplicity of use.
II. Modifiability
This attribute defines the maintainability and modifiability of this feature/functionality. Considerations to the ease of making changes all the way to the availability of resources with the technical knowledge to support the feature/functionality are addressed here.
III. Performance
This attributes defines the performance qualities for this feature/functionality. Response times, processing times, etc. should be considered.
IV. Availability
This attribute defines what qualities pertain to how available this feature/functionality must be to users and other systems. Failover, recovery times, etc. would be considered here.
V. Security
This attribute defines the security qualities that define this feature/functionality. Elements as in protecting access, data, etc. should be considered.
VI. Testability
This attribute defines the quality attributes for testing this feature/function. Ease of testing – including Unit as well as QA are considered. Special attention to quality controls like test automation, heartbeats, dashboards that self test are also included in these considerations.
VII. Scalability
This attribute defines how this feature/functionality scales. Overall capacity should be considered at this point including future growth.
VIII. Portability
This attribute defines the portability of this functionality – Cross Plattform functionality as well as maintaining a light interdependence on common vendor functdionality (i.e.WebServers: JBoss vs Weblogic &/or WebSphere).
IX. Business Qualities
A. Time
This attribute defines the time constraints to deliver this functionality..
B. Cost (CBA)
This attribute defines the cost benefit of this functionality.
C. Market
This attribute defines the market segmentation of this functionality. Since we aren’t really managing to a Product Line, I’m OK with Omitting this in our definitions of architecture.
D. Integration
This attribute discusses the system integration of this functionality to other systems
E. Lifetime
This attribute defines the expected time this product is expected to exist, iterations that are expected to impact it, etc.
The 4 building blocks of Architecting Systems for Scale
A quick gloss on the building blocks:
In this post I'll attempt to document some of the scalability architecture lessons learned while working on systems at Yahoo! and Digg.
I've attempted to maintain a color convention for diagrams in this post:
Load Balancing: Scalability & Redundancy
The ideal system increases capacity linearly with adding hardware. In such a system, if you have one machine and add another, your capacity would double. If you had three and you add another, your capacity would increase by 33%. Let's call this horizontal scalability.
On the failure side, an ideal system isn't disrupted by the loss of a server. Losing a server should simply decrease system capacity by the same amount it increased overall capacity when it was added. Let's call this redundancy.
Both horizontal scalability and redundancy are usually achieved via load balancing.
(This article won't address vertical scalability, as it is usually an undesirable property for a large system, as there is inevitably a point where it becomes cheaper to add capacity in the form on additional machines rather than additional resources of one machine, and redundancy and vertical scaling can be at odds with one-another.)
Load balancing is the process of spreading requests across multiple resources according to some metric (random, round-robin, random with weighting for machine capacity, etc) and their current status (available for requests, not responding, elevated error rate, etc).
Load needs to be balanced between user requests and your web servers, but must also be balanced at every stage to achieve full scalability and redundancy for your system. A moderately large system may balance load at three layers: from the
Smart Clients
Adding load-balancing functionality into your database (cache, service, etc) client is usually an attractive solution for the developer. Is it attractive because it is the simplest solution? Usually, no. Is it seductive because it is the most robust? Sadly, no. Is it alluring because it'll be easy to reuse? Tragically, no.
Developers lean towards smart clients because they are developers, and so they are used to writing software to solve their problems, and smart clients are software.
With that caveat in mind, what is a smart client? It is a client which takes a pool of service hosts and balances load across them, detects downed hosts and avoids sending requests their way (they also have to detect recovered hosts, deal with adding new hosts, etc, making them fun to get working decently and a terror to get working correctly).
Hardware Load Balancers
The most expensive--but very high performance--solution to load balancing is to buy a dedicated hardware load balancer (something like a Citrix NetScaler). While they can solve a remarkable range of problems, hardware solutions are remarkably expensive, and they are also "non-trivial" to configure.
As such, generally even large companies with substantial budgets will often avoid using dedicated hardware for all their load-balancing needs; instead they use them only as the first point of contact from user requests to their infrastructure, and use other mechanisms (smart clients or the hybrid approach discussed in the next section) for load-balancing for traffic within their network.
Software Load Balancers
If you want to avoid the pain of creating a smart client, and purchasing dedicated hardware is excessive, then the universe has been kind enough to provide a hybrid approach: software load-balancers.
HAProxy is a great example of this approach. It runs locally on each of your boxes, and each service you want to load-balance has a locally bound port. For example, you might have your platform machines accessible via localhost:9000, your database read-pool at localhost:9001 and your database write-pool at localhost:9002. HAProxy manages healthchecks and will remove and return machines to those pools according to your configuration, as well as balancing across all the machines in those pools as well.
For most systems, I'd recommend starting with a software load balancer and moving to smart clients or hardware load balancing only with deliberate need.
Caching
Load balancing helps you scale horizontally across an ever-increasing number of servers, but caching will enable you to make vastly better use of the resources you already have, as well as making otherwise unattainable product requirements feasible.
Caching consists of: precalculating results (e.g. the number of visits from each referring domain for the previous day), pre-generating expensive indexes (e.g. suggested stories based on a user's click history), and storing copies of frequently accessed data in a faster backend (e.g. Memcache instead of PostgreSQL.
In practice, caching is important earlier in the development process than load-balancing, and starting with a consistent caching strategy will save you time later on. It also ensures you don't optimize access patterns which can't be replicated with your caching mechanism or access patterns where performance becomes unimportant after the addition of caching (I've found that many heavily optimized Cassandra applications are a challenge to cleanly add caching to if/when the database's caching strategy can't be applied to your access patterns, as the datamodel is generally inconsistent between the Cassandra and your cache).
Application Versus Database Caching
There are two primary approaches to caching: application caching and database caching (most systems rely heavily on both).
Application caching requires explicit integration in the application code itself. Usually it will check if a value is in the cache; if not, retrieve the value from the database; then write that value into the cache (this value is especially common if you are using a cache which observes the least recently used caching algorithm). The code typically looks like (specifically this is a read-through cache, as it reads the value from the database into the cache if it is missing from the cache):
key = "user.%s" % user_id
user_blob = memcache.get(key)
if user_blob is None: user = mysql.query("SELECT * FROM users WHERE user_id=\"%s\"", user_id)
if user:
memcache.set(key, json.dumps(user))
return user
else:
return json.loads(user_blob)
The other side of the coin is database caching.
When you flip your database on, you're going to get some level of default configuration which will provide some degree of caching and performance. Those initial settings will be optimized for a generic usecase, and by tweaking them to your system's access patterns you can generally squeeze a great deal of performance improvement.
The beauty of database caching is that your application code gets faster "for free", and a talented DBA or operational engineer can uncover quite a bit of performance without your code changing a whit (my colleague Rob Coli spent some time recently optimizing our configuration for Cassandra row caches, and was succcessful to the extent that he spent a week harassing us with graphs showing the I/O load dropping dramatically and request latencies improving substantially as well).
In Memory Caches
The most potent--in terms of raw performance--caches you'll encounter are those which store their entire set of data in memory. Memcached andRedis are both examples of in-memory caches (caveat: Redis can be configured to store some data to disk). This is because accesses to RAM are orders of magnitudefaster than those to disk.
On the other hand, you'll generally have far less RAM available than disk space, so you'll need a strategy for only keeping the hot subset of your data in your memory cache. The most straightforward strategy is least recently used, and is employed by Memcache (and Redis as of 2.2 can be configured to employ it as well). LRU works by evicting less commonly used data in preference of more frequently used data, and is almost always an appropriate caching strategy.
Content Distribution Networks
A particular kind of cache (some might argue with this usage of the term, but I find it fitting) which comes into play for sites serving large amounts of static media is the content distribution network.
CDNs take the burden of serving static media off of your application servers (which are typically optimzed for serving dynamic pages rather than static media), and provide geographic distribution. Overall, your static assets will load more quickly and with less strain on your servers (but a new strain of business expense).
In a typical CDN setup, a request will first ask your CDN for a piece of static media, the CDN will serve that content if it has it locally available (HTTP headers are used for configuring how the CDN caches a given piece of content). If it isn't available, the CDN will query your servers for the file and then cache it locally and serve it to the requesting user (in this configuration they are acting as a read-through cache).
If your site isn't yet large enough to merit its own CDN, you can ease a future transition by serving your static media off a separate subdomain (e.g. static.example.com) using a lightweight HTTP server like Nginx, and cutover the DNS from your servers to a CDN at a later date.
Cache Invalidation
While caching is fantastic, it does require you to maintain consistency between your caches and the source of truth (i.e. your database), at risk of truly bizarre applicaiton behavior.
Solving this problem is known as cache invalidation.
If you're dealing with a single datacenter, it tends to be a straightforward problem, but it's easy to introduce errors if you have multiple codepaths writing to your database and cache (which is almost always going to happen if you don't go into writing the application with a caching strategy already in mind). At a high level, the solution is: each time a value changes, write the new value into the cache (this is called a write-through cache) or simply delete the current value from the cache and allow a read-through cache to populate it later (choosing between read and write through caches depends on your application's details, but generally I prefer write-through caches as they reduce likelihood of a stampede on your backend database).
Invalidation becomes meaningfully more challenging for scenarios involving fuzzy queries (e.g if you are trying to add application level caching in-front of a full-text search engine likeSOLR), or modifications to unknown number of elements (e.g. deleting all objects created more than a week ago).
In those scenarios you have to consider relying fully on database caching, adding aggressive expirations to the cached data, or reworking your application's logic to avoid the issue (e.g. instead of DELETE FROM a WHERE..., retrieve all the items which match the criteria, invalidate the corresponding cache rows and then delete the rows by their primary key explicitly).
Off-Line Processing
As a system grows more complex, it is almost always necessary to perform processing which can't be performed in-line with a client's request either because it is creates unacceptable latency (e.g. you want to want to propagate a user's action across a social graph) or it because it needs to occur periodically (e.g. want to create daily rollups of analytics).
Message Queues
For processing you'd like to perform inline with a request but is too slow, the easiest solution is to create a message queue (for example, RabbitMQ). Message queues allow your web applications to quickly publish messages to the queue, and have other consumers processes perform the processing outside the scope and timeline of the client request.
Dividing work between off-line work handled by a consumer and in-line work done by the web application depends entirely on the interface you are exposing to your users. Generally you'll either:
Scheduling Periodic Tasks
Almost all large systems require daily or hourly tasks, but unfortunately this seems to still be a problem waiting for a widely accepted solution which easily supports redundancy. In the meantime you're probably still stuck with cron, but you could use the cronjobs to publish messages to a consumer, which would mean that the cron machine is only responsible for scheduling rather than needing to perform all the processing.
Does anyone know of recognized tools which solve this problem? I've seen many homebrew systems, but nothing clean and reusable. Sure, you can store the cronjobs in a Puppetconfig for a machine, which makes recovering from losing that machine easy, but it would still require a manual recovery, which is probably acceptable but not quite perfect.
Map-Reduce
If your large scale application is dealing with a large quantity of data, at some point you're likely to add support for map-reduce, probably using Hadoop, and maybeHive or HBase.
Adding a map-reduce layer makes it possible to perform data and/or processing intensive operations in a reasonable amount of time. You might use it for calculating suggested users in a social graph, or for generating analytics reports.
For sufficiently small systems you can often get away with adhoc queries on a SQL database, but that approach may not scale up trivially once the quantity of data stored or write-load requires sharding your database, and will usually require dedicated slaves for the purpose of performing these queries (at which point, maybe you'd rather use a system designed for analyzing large quantities of data, rather than fighting your database).
Platform Layer
Most applications start out with a web application communicating directly with a database. This approach tends to be sufficient for most applications, but there are some compelling reasons for adding a platform layer, such that your web applications communicate with a platform layer which in turn communicates with your databases.
First, separating the platform and web application allow you to scale the pieces independently. If you add a new API, you can add platform servers without adding unnecessary capacity for your web application tier. (Generally, specializing your servers' role opens up an additional level of configuration optimization which isn't available for general purpose machines; your database machine will usually have a high I/O load and will benefit from a solid-state drive, but your well-configured application server probably isn't reading from disk at all during normal operation, but might benefit from more CPU.)
Second, adding a platform layer can be a way to reuse your infrastructure for multiple products or interfaces (a web application, an API, an iPhone app, etc) without writing too much redundant boilerplate code for dealing with caches, databases, etc.
Third, a sometimes underappreciated aspect of platform layers is that they make it easier to scale an organization. At their best, a platform exposes a crisp product-agnostic interface which masks implementation details. If done well, this allows multiple independent teams to develop utilizing the platform's capabilities, as well as another team implementing/optimizing the platform itself.
I had intended to go into moderate detail on handling multiple data-centers, but that topic truly deserves its own post, so I'll only mention that cache invalidation and data replication/consistency become rather interesting problems at that stage.
I'm sure I've made some controversial statements in this post, which I hope the dear reader will argue with such that we can both learn a bit. Thanks for reading!
Source: http://lethain.com/introduction-to-architecting-systems-for-scale/
The 7 stages of scaling web apps
Good presentation of the stages a typical successful website goes through:
Prime directive of scaling: Think Horizontally at every point in your architecture, not just at the web tier. You may not agree with everything, but there's a lot of useful advice. Here's a summary:
I’ve spent the last five years implementing and thinking about service oriented architectures. One of the core benefits of a service oriented approach is the promise of greatly enhanced scalability and redundancy. But to realise these benefits we have to write our services to be ‘scalable’. What does this mean?
There are two fundamental ways we can scale software: 'Vertically' or 'horizontally'.
Is Hibernate the best choice?
Is Hibernate the best choice? Or is the technical marketing of other ORM vendors lacking? Recently Jonathan Lehr posed a question on his blog: "Is Hibernate the best choice?", and this lead me to ask the same question.
Although, I tend to use Hibernate as my first choice, it would be nice to see some head to head comparisons of Hibernate vs. TopLink (pros and cons), Hibernate vs. OpenJPA, Hibernate vs. Cayenne, etc. Searching around finds that many of the comparison are pretty old and not very detailed or compelling.
Having used other ORM frameworks, I found that when something goes wrong with Hibernate, you can usually google and find an answer, and there are many books on Hibernate. In my experience, the other frameworks seemed to be a less well-worn path and it is harder to find answers to even common problems. This is not to say that Hibernate is better, but that it is a lot more popular. In the end, I use Hibernate because my clients use it, if my clients switched to TopLink or OpenJPA, then I would use them as well.
So this begs the question, if Hibernate works for you, you just might have something else to do, like implementing a client solution that makes your client money, than to try several other ORM frameworks. How much time should someone spend learning a new ORM framework (new to them anyway)?
Don't get this wrong, trying out new ORM frameworks is fine. If there is a large IT/developer organization, and you have a certain selection criteria like integrating with legacy databases, conformance to JPA specification, ability to hire new developers, easy of use, etc. then by all means having someone create a few prototypes and/or proofs of concepts and try out a few ORM frameworks is great. There is often good ROI in this type of testing. Perhaps share your findings with the rest of us.
However, it seems if you are a vendor of a JPA solution, you could start by pointing out how your product differs from Hibernate. Like it or not, Hibernate dominates the mind-share of developers. If you can't prove your ORM frameworks has compelling reasons for switching, why should developers spend their time evaluating your product?
Now let me boil things down to brass tacks, it seems vendors of the ORMs should write white-papers, articles, blogs, and such to highlight the advantages of their ORM framework versus Hibernate. Logic dictates that if you have a product and there is a competing product that dominates the market that you might want to highlight what differentiates your product from the dominate one.
As a test, let's go to different vendor sites and see if they have comparisons of their ORM framework vs. the 800 pound gorilla, Hibernate.
So first let's go to Oracle TopLink website, you would expect since Hibernate has such a huge adoption rate in the industry that Oracle would want to point out why TopLink is better like a nice white-paper perhaps featured prominently on their TopLink site (see graph).
After hunting around a bit this entry appeared in the TopLink Essentials FAQ, Why should TopLink Essentials be used instead of JBoss(TM) Hibernate?
The two main points that seemed intriguing were as follows:
"Customers with any degree of complexity in the domain model or relational schemas, most notably where changing the schema is not an option, will benefit from the flexibility and proven nature of TopLink."
NOTE: At times mapping Hibernate to legacy systems can be challenging. How is TopLink better at this? Are there articles or white-papers, etc. that attempt to prove that TopLink is better at legacy integration? (I find that many developers are not aware of all of the features that Hibernate provides for legacy mapping.)
"As the reference implementation of JPA TopLink offers the first certified implementation of this new standard. as well as providing some useful value-add functionality. Going forward this open source project will continue to innovate based on contributions from Oracle, Sun, and others."
NOTE: This is compelling to me since I now use the JPA interface to Hibernate whenever I can.
Now I did not find the arguments in the FAQ particularly compelling or at all detailed. Sadly, you can find more compelling arguments in some of the TopLink public forums and random blogs. However, none so compelling that I feel the sudden need to switch.
Now on to the BEA site to look at dear KODO. I have always heard good things about KODO. Sadly, I found the BEA KODO site to be very out of date. It mentions a 2005 award for KODO as the lead news item. It also mentions that OpenJPA is in incubation, it has been out for a while. Even the FAQ, which did mention Hibernate, merely mentions that Hibernate is not EJB3 (seems it should say Hibernate is not JPA). This site really seems out of date and like the TopLink site mosty ignores the elephant in the room (see graph).
Well, let's look at the Apache OpenJPA site, as KODO's DNA may live at Apache long after Oracle decides on a single JPA solutions and likely leaves KODO to rot on the vine. Searching through the main site, FAQ, OpenJPA documentation, etc., I find no mention of Hibernate. Now this is an open source project so one would likely expect to see no marketing angle per se. But, you might expect that a project recognize that many would not be able to use this project without first justifying their pick against picking Hibernate (OpenJPA barely appears at all on job graphs). How many IT/development managers will feel comfortable with this choice without some explanation?
Now on to the next ORM framework site, Cayenne. No mention of Hibernate vs. Cayenne (but I know I have read articles on this). Seems like there might be some compelling ease-of-use arguments for Cayenne vs. Hibernate but they choose not to compare them. (Cayenne barely appears at all on job graphs)
Now back to Jonathan Lehr blog, Jonathan states that he feels TopLink and Cayenne are better choices than Hibernate and cites his reasons for these choices. There is a long discussion on the pros and cons of each in the comment section. I'd love to see more discussion, and I'd love to see some viable alternatives to Hibernate, but feel that no vendor or open source project does a real good job of pointing out the differences and possible limitations of Hibernate. If the vendors and project owners choose not to make their case, it makes it very difficult for the rank and file developers to make their case.
Perhaps one reason Hibernate is so dominate is because competing projects are so bad at technical marketing. Not one project I looked at mentions Hibernate on their front page. I could not find a decent comparison of features (to Hibernate's) on any of the ORM sites.
Has anyone done a comparison of Hibernate and OpenJPA, TopLink Essentials, Cayenne that compares ease-of-use, caching, tool support, legacy integration, etc.? Perhaps such an internal report was used to decide which ORM tool to pick. If so, what were the results?
If you use TopLink, OpenJPA, Cayenne instead of Hibernate, why?
Were you hoping that JPA would level the playing field and there would be more competition?
Cassandra Adds Hadoop MapReduce
Today the Cassandra project announced its first new release since becoming a Top-Level Project at Apache. Don't let the low version number fool you. Cassandra 0.6 is one of the most mature NoSQL distributed data stores in the open source market. It was heavily developed by Facebook before it was open sourced in August 2008. Currently Cassandra is being used by four of the largest social media sites in the world: Facebook, Digg, Reddit, and Twitter.
One of the primary new features in Cassandra 0.6 is support for Apache Hadoop. This is a major upgrade for Cassandra, giving it even more "big data" capabilities. The new feature will allow Cassandra to run analytics against its own data using Hadoop's reliable MapReduce framework.
Cassandra 0.6 simplifies its architecture with a new integrated caching row. With the implementation of this new feature, Cassandra no longer needs a separate caching layer. Along with the simplified architecture, Cassandra 0.6 also features a performance boost. The distributed data store can already process thousands of writes per second, and this version's enhancements builds on that number.
"Apache Cassandra 0.6 is 30% faster across the board, building on our already-impressive speed," said Jonathan Ellis, Apache Cassandra Project Management Committee Chair in the press release. "It achieves scale-out without making the kind of design compromises that result in operations teams getting paged at 2 AM." The Storage Team Technical Lead at Twitter, Ryan King, explained Twitter's reasons for using Cassandra: "At Twitter, we're deploying Cassandra to tackle scalability, flexibility and operability issues in a way that's more highly available and cost effective than our current systems."
One of Cassandra's best known features is its lack of any single point of failure. The data store's distributed system smoothly replaces any node that goes down with a new node. The system also has the flexibility to be tuned for more consistency or more availability.
The previous version of Cassandra (0.5) added load balancing and significantly improved bootstrap and concurrency. New tools were also added, including JSON-based data import and export, new JMX metrics, and an improved command line interface. “It's fantastic seeing the Project's community at the ASF grow to match the promise of the technology," said Ellis.
You can download Cassandra 0.6 now on the project's website. For more info on Cassandra, check out "4 Months with Cassandra, a love story."
Cache selection(POC) for one of my product
Introduction
The purpose of this document is to define a new cache implementation for one of my product. This new cache implementation is proposed to improve the scalability, manageability, and distribution of cache items in the my Platform.
Current Cache Issues
The following sections define the most critical problems with the current cache implementation of which the proposed new cache solution will address.
Multiple Cache Copies
The current cache implementation is designed such that a complete copy of the cache exists on every application server in which our Product is deployed. With this design, as clients and data are added to the cache in an instance of a our platform product the amount of memory taken up by the cache increases linearly with the amount of data added to it. The result of this increase in memory per client and data item added takes away from application server memory thus limiting the overall scalability of the platform. As memory increases due to new clients and data, adding application server machines to handle increased load has less and less of an effect because of the amount of memory taken away from the application itself by the cache.
As clients (and products) are added to the system the amount of memory allocated by the cache increases until adding machines to the cluster to handle performance load (CPU) issues has no effect due to memory constraints and a new separate application cluster would need to be created. Once the client/application threshold is reached in terms of memory, the footprint of all the machines in the cluster will look like the 10 client footprint .
Cache Reload Time
Another side effect of having an instance of the cache in each application server is if an application server must be restarted or shut down for any reason the data in the cache is cleared. When the application is restarted the cached data must be reloaded from the database. The time to reload the cache can be considerable and will only increase as we add clients and data to the cache over time. The time it takes to reload the cache directly increases the amount of downtime required to make code or other modifications requiring a restart of the system. The reloading of the cache is especially time consuming in the current cache implementation since most of the items in the cache are loaded at startup instead of as-needed.
Cache Item Update Complexity
The current cache implementation also has the added complexity of updating other application servers participating in a our Product cluster when a cached item is modified. For example, if a cache item is modified in Machine 1 of a cluster of 5 Machines then the item must also be sent to the modified item must also be updated in caches of the remaining 4 machines. Up to this time, this distributed cache process has been problematic during restarts and there is no 100pct certainty that modified cache items are distributed properly to the other machines participating in the cluster.
Proposed Solution to the Current Cache Issues
In order to solve the issues of the current cache implementation, a distributed-hash based cache solution is proposed. In a distributed-hash based cache (DHBC) implementation the cache is extracted from the application servers and resides in a separate cluster of cache machines. The DHCB cluster acts as a single very large cache limited only by the total memory of all the machines participating in the cluster. So for example if there are four machines in the DHBC cluster each with 4GB of RAM then the DHBC cluster capacity will be 16GB minus whatever memory the operating system and required apps need.
The distributed-hash algorithm determines which cache cluster machine in which to connect. Once an item is added to the cache by a member of the application server cluster, the item is available to all members of the application server cluster without having to distribute it.
Cache Items in a DHBC
A cache item in a DHBC cluster exists only once in the cache. When an item is requested from the DHBC the distributed hash algorithm determines on which machine the cache item resides and returns the appropriate item if it exists. The distributed hash algorithm also determines on which machine to put a new cache item. As new machines are added to the DHBC cluster the distributed hash algorithm automatically adjusts itself and uses the new machine as part of the overall cache.
If a machine participating in a DHBC cluster goes down, the distributed hash algorithm is designed to adapt to the fact that a participating machine is down. Any new cached items will be added to the remaining servers and items that were in the downed server must be added again to the distributed cache.
Load on Demand Additionally, in order to be as fault-tolerant as possible the cache strategy must be changed from a “load once at startup and update” strategy to a “load on demand” strategy. If a “load on demand” strategy is employed by the application programmers then the application itself will be insulated from issues that may arise if any machines participating in the DHBC cluster fail. A “load on demand” strategy means if item already exists in the cache when requested then return it, otherwise add it to the cache so new requests for the cached item will have it. In this case, if a machine participating in the DHBC cluster fails and a cached item is not returned then simply add it again to the cache. The only issue will be a slight performance hit when the cached items in the failed machine are reloaded into the cache as they are requested.
Cache Updates
Cache updates are much less complex in a DHBC implementation than the existing cache solution. If an item is added to the cache or replaced with a new value the item is automatically available to any application that requests it. The item does not need to be distributed to other servers in the cluster (application or otherwise).
Effects on Application Reload Time
Since the items in a DHBC cluster do not reside within the application server, the application servers can be stopped and restarted without affecting the cache. So, if an application server needs to be restarted because of a code change or other maintenance the application server can be started much more quickly since the cache does not need to be reloaded. Additionally, the newly started server will have access to any new items that were added or updated to the cache while the server application server was down for maintenance.
Implementing the DHBC
In order to implement the DHBC it is required to have a DHBC implementation itself and a client from which to access the HDBC cluster. For this purpose it is recommended to use the Linux based memcached implementation. Note that the client itself is available in most languages and platforms and does need to run on a Linux platform.
Memcached
Memcached is commonly available for most Linux distributions and has been used extensively by Facebook and many other websites as well as the MySQL database and Hibernate database library to provide scalable easy to use cache implementations. Memcached and the clients that use it are all open sourced so we can acquire the source code and modify it if necessary.
Information on memcached can be acquired from the following web site:
http://www.danga.com/memcached/
The list of memcached clients that can be used for each programming language is found here:
http://code.google.com/p/memcached/wiki/Clients
Sample code for each of the clients can be acquired from the above web site. However, for initial testing I have used the spymemcached client listed on the above web site and some sample code of my own for it be needed.
Hash Key The most important part of implementing the DHCB will be the choice of hash key. The hash key is used to uniquely identify a hash item in the DHCB. I recommend a key like the following:
< DISCRIMINATOR>.<APPLICATION>.<CLIENT>.<VALUE_KEY>
Where DISCRIMINATOR can be anything desired such as “TestEnvironment” or another grouping, APPLICATION is an application identifier such as “OurProduct”, CLIENT is either “ANY_CLIENT” or a specific client such as “WalMart”, and the VALUE_KEY can be anything appropriate.
For example if the DISCRIMINATOR is“JeffsTests”, the APPLICATION is “OurProduct”, the value is shared across clients, and the VALUE_KEY is page.login.firstNamethen the key would be “JeffsTests.OurProduct.ANY_CLIENT.page.login.userName”. The example key is for clarity but the key components can be abbreviated and shortened.
The <DISCRIMINATOR> in the key strategy allows multiple installations (or developers or testers or environments) to use the same memcached instance without interfering with each other.
This key strategy should be flexible enough for our present and future needs but can be enhanced as better ideas arise.
Memcached Environment
There is a test environment with the memcached server installed and already set up on two Ubuntu Linux servers. The IP addresses, user names, and passwords are available on request. It is necessary to download and install an SSH client to connect to and use the Linux servers from a windows desktop. A reasonable choice is the freely available putty (http://www.chiark.greenend.org.uk/~sgtatham/putty/) SSH client.
Implementation in Existing product
To implement memcached in the existing product it is recommended to create a switch value that can switch between memcached implementation and the existing design until developers, hosting, and others get used to working with memcached. The existing design can then be phased out whenever is appropriate.
In addition to the switch above, the cache strategy in the existing product should be changed to a “load on demand” strategy as defined in the Load on Demand section of this document. If, after implementing the“load on demand” strategy it is still required or desired to load very frequently and/or first used information into the cache then a routine to seed the cache by simply requesting keys for those items can be put in place.
It is required to implement an appropriate cache key strategy similarly to the strategy defined in the Hash Key section of this document.
Tools and utilities should also be created to check the number of keys, memory allocated, and other statistical information about the cache. The statistical tools should be compatible with the SiteMonitor program hosting uses to check for failures to ensure any production issues are quickly identified.
Additionally, routines should be created to allow for selective deletion and arbitrary viewing of items in the cache for maintenance reasons such as removing clients and debugging.
Testing
Since the cache implementation touches virtually every component of the our Product and related applications, once implementation in our product is completed a full functional regression test of the Applications making use of the cache needs to be performed. Additionally, the usual load tests should be performed as well to address any performance concerns.
Deployment
It is recommended that there be at least three memcached environments be deployed after implementation is complete. The three environments are Production, Staging, and QA/Development. QA and Development can make use of the< DISCRIMINATOR> value in the key to isolate key items from development and testing efforts. Another environment can be created if it is not desired to have QA and development using the same machines.
There should be at least two servers in the memcached cluster to allow for fault tolerance, complete testing, and scalability. In the production environment I recommend at least three servers to make sure that if a machine goes down there is ample room in the cluster to handle the cached items in the failed server. For example, if it takes 4GB to cache all the required data I would recommend three machines with at least 2GB of memory so the remaining clusters can handle the cache requirements without the third machine. It is also important to make sure the network connecting the application server machines and the DHBC cluster is a fast and fault tolerant as possible to avoid bottlenecks and performance issues.
More Possibilities
In addition to replacing the existing cache mechanism used by our product the DHBC can be used for other functions as well. Since the amount of memory available to a DHBC cluster is very large (some implementations have terabytes) depending on the capacity and number of machines in the cluster, the cache can be used to keep almost anything in memory.
One possible example might be to cache the complete list of candidates or jobs for an important client to get extreme performance and take load away from the database. Other possibilities include anything that can take the load off the database such as caching frequently searched result sets and expiring them after a certain amount of time. It also should be possible to cache frequently accessed assets (pdf files, other documents, user uploaded images, etc.) and dynamically generated html pages (if they don’t change much).
Since the DHBC is shared across applications it should be possible to use it as a session sharing mechanism or general utility to keep information available for shared application usage without hitting the database.
Once the cache is complete, available, and tested, more thought should be done to find new imaginative ways in which the cache can be leveraged to improve performance and scalability in our applications.
MemCachedVsEhCache
Overview
Two distributed cache servers; Ehcache (Distributed Caching With Terracotta) and Memcached were evaluated to determine which one better fits the needs of our product. They were evaluated in various areas including ease of configuration, API usage, and overall speed.
Hardware
Client Machine:
AMD Sempron 2800+
1.61. GHz, 2 GB RAM
Windows Server 2003, Service Pack 2
Server Machine:
Dell Optiplex 740
Intel Core 2 CPU 6700
2.66 GHz, 1 GB RAM
Windows Server 2003, Service Pack 2
Software
Memcached Software:
Server:memcached-x86 1.4.5 binary for Windows
Test Client:spymemcached 2.5
Ehcache Software:
Server:terracotta-3.4.0 (Single Server Array)
Test Client:Ehcache 2.3.1
Configuration
Both cache servers were relatively easy to setup. For Memcached, a windows 1.4.5 version binary (memcached.exe) was used (I can’t recall the source url). Running memcached –h gives a list of the available options. For this evaluation memcached –m was the only option used to specify the maximum amount of memory to allow. For Ehcache, Ehcache 2.3.1 (ehcache-core-2.3.1-distribution.tar.gz) along with Terracotta 3.4.0 (terracotta-3.4.0_1-installer.jar) was downloaded from http://ehcache.org. The Terracotta installer, invoked with java -jar terracotta-3.4.0_1-installer.jar was easy to follow. The server can be started using the bin\start-tc-server.bat script in the installation folder. In summary, both cache servers are relatively easy to configure. I would probably give the edge here to Ehcache simply because there is a wealth of options available and they are well documented. Additionally, Ehcache uses a configuration file (ehcache.xml), which allows for different cache configurations which are selected at runtime.
API Usage
Both API’s are relatively simple to use. Adding, retrieving and deleting elements is straightforward.
Ehcache
import net.sf.ehcache.Cache;
import net.sf.ehcache.CacheManager; import net.sf.ehcache.Element;
public class Ehcache implements ICache
{
CacheManager mCacheManager;
Cache mCache;
public void init() throws Exception
{
InputStream fis = new FileInputStream(new File(<config file>))
try
{
mCacheManager = new CacheManager(fis);
mCache = mCacheManager.getCache(<cache name>);
}
finally
{
fis.close();
}
}
public void put(String pKey,Object pValue) throws Exception
{
mCache.put(new Element(pKey,pValue)); }
public Object get(String pKey) throws Exception
{
Element lElement = mCache.get(pKey);
if (lElement != null)
return lElement.getObjectValue();
return null;
}
public void remove(String pKey) throws Exception
{
mCache.remove(pKey);
}
}
MemCached
import java.net.InetSocketAddress;
import java.util.Arrays;
import net.spy.memcached.MemcachedClient;
import com.kenexa.core.data.dhbc.system.memcached._DefaultConnectionFactory;
public class Memcached implements ICache
{
MemcachedClient mMemcachedClient;
public void init() throws Exception
{
String lHost = "192.168.10.101";
int lPort = 11211;
InetSocketAddress address = new InetSocketAddress(lHost,lPort);
mMemcachedClient = new MemcachedClient(new _DefaultConnectionFactory(), Arrays.asList(address));
}
public void put(String pKey,Object pValue) throws Exception
{
mMemcachedClient.set(pKey,3600,pValue);
}
public Object get(String pKey) throws Exception
{
return mMemcachedClient.get(pKey);
}
public void remove(String pKey) throws Exception
{
mMemcachedClient.delete(pKey);
}
}
Ehcache additionally provides the ability to iterate the keys in the cache and extract statistical and other information which can be used to implement custom analysis tools. For this reason, I would rate Ehcache’s API better.
Performance
In order to evaluate the performance of both cache servers, the add, retrieve and remove operations were compared.
Test 1: Add
In the first test, fixed sized random byte arrays were added to the cache and the time to complete each set in milliseconds was recorded. I started with Ehcache and added 1000 random byte arrays of 1K, 10K and 100K followed by 10000 arrays of 1K and 10K. Finally, 2500 100K and 500 500K arrays were added. Each test was ran three (3) times to ensure the results were valid and the server software was stopped and restarted for each test to allow for consistent results. I then repeated the same tests for Memcached. The median result for each test is posted below.
Result:
Memcached’s outperformed Ehcache in these tests. I had initially collected some baseline numbers by running the same tests using only the client machine to host both the test client and cache server and the results were consistent with using two servers.
Add 1000 1K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 4750
Memcached 781
Add 1000 10K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 5500
Memcached 2078
Add 1000 100K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 18547
Memcached 4735
Add 10000 1K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 28094
Memcached 9360
Add 10000 10K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 38718
Memcached 11094
Add 2500 100K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 44937
Memcached 12531
Add 500 500K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 35953
Memcached 14500
Test 2: Add – Remove
In this test, fixed sized random byte arrays were added and removed from the cache and the time to complete each set in milliseconds was recorded. I started with Ehcache and added/removed 1000 random byte arrays of 1K, 10K and 100K followed by 10000 arrays of 1K and 10K. Finally, 2500 100K and 500 500K arrays were added/removed. Each test was ran three (3) times to ensure the results were valid and the server software was stopped and restarted for each test to allow for consistent results. I then repeated the same tests for Memcached. The median result for each test is posted below.
Result:
Memcached’s performance was again faster in this scenario.
Add-Remove 1000 1K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 6047
Memcached 1204
Add-Remove 1000 10K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 6578
Memcached 2891
Add-Remove 1000 100K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 17109
Memcached 5516
Add-Remove 10000 1K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 33172
Memcached 15641
Add-Remove 10000 10K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 37828
Memcached 20875
Add-Remove 500 500K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 34500
Memcached 14468
Add-Remove 2500 100K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 44766
Memcached 14141
Test 3: MultiThreaded Get for 15 minutes
In this test, 1000 100K random byte arrays were first loaded to each cache server. Ten (10) threads were then created in the test client and each thread repeatedly retrieved random elements from the cache. A checksum was included with the added data and used during retrieval to ensure that the data was valid. Each test ran for 15 minutes to see how many records could be retrieved in that time period. There was no delay between operations. The average retrieval time per thread is also included.
Result:
Ehcache
runGetTestThreaded(Ehcache,1000 elements,size[102400] - 10 threads : 900 secs)
Thread Thread[Thread-19,5,] count = 8096, Avg Get Time = 110.49085968379447
Thread Thread[Thread-20,5,] count = 8072, Avg Get Time = 110.78889990089198
Thread Thread[Thread-21,5,] count = 8188, Avg Get Time = 109.18075232046898
Thread Thread[Thread-22,5,] count = 8143, Avg Get Time = 109.89942281714356
Thread Thread[Thread-23,5,] count = 8097, Avg Get Time = 110.44646165246388
Thread Thread[Thread-24,5,] count = 8054, Avg Get Time = 111.07946362056121
Thread Thread[Thread-25,5,] count = 8144, Avg Get Time = 109.85940569744598
Thread Thread[Thread-26,5,] count = 8094, Avg Get Time = 110.57289350135903
Thread Thread[Thread-27,5,] count = 8040, Avg Get Time = 111.2957711442786
Thread Thread[Thread-28,5,] count = 8129, Avg Get Time = 110.07467093123385
Total Count = 81057
Memcached
runGetTestThreaded(Memcached,1000 elements,size[102400] - 10 threads : 900 secs
Thread Thread[Thread-1,5,] count = 9580, Avg Get Time = 93.30365344467641
Thread Thread[Thread-2,5,] count = 9579, Avg Get Time = 93.33312454327174
Thread Thread[Thread-3,5,] count = 9579, Avg Get Time = 93.35369036433866
Thread Thread[Thread-4,5,] count = 9579, Avg Get Time = 93.3253993109928
Thread Thread[Thread-5,5,] count = 9579, Avg Get Time = 93.35953648606326
Thread Thread[Thread-6,5,] count = 9581, Avg Get Time = 93.27439724454649
Thread Thread[Thread-7,5,] count = 9581, Avg Get Time = 93.29683749086735
Thread Thread[Thread-8,5,] count = 9581, Avg Get Time = 93.25988936436697
Thread Thread[Thread-9,5,] count = 9580, Avg Get Time = 93.27651356993736
Thread Thread[Thread-10,5,] count = 9580, Avg Get Time = 93.25490605427974
Total Count = 95799
Memcached performance was slightly faster in this test. As it terms out, Ehcache has an option maxElementsInMemory, which sets the maximum number of objects that will be created in memory. Setting this value to 1000 and restarting the test yields the following results.
runGetTestThreaded(Ehcache,1000 elements,size[102400] - 10 threads : 900 secs)
Thread Thread[Thread-19,5,] count = 188456, Avg Get Time = 0.06041728573247867
Thread Thread[Thread-20,5,] count = 187452, Avg Get Time = 0.06884429080511277
Thread Thread[Thread-21,5,] count = 188048, Avg Get Time = 0.046940142942227515
Thread Thread[Thread-22,5,] count = 189150, Avg Get Time = 0.0383187946074544
Thread Thread[Thread-23,5,] count = 186504, Avg Get Time = 0.05214365375541544
Thread Thread[Thread-24,5,] count = 191792, Avg Get Time = 0.06031534162008843
Thread Thread[Thread-25,5,] count = 187647, Avg Get Time = 0.046033243270609175
Thread Thread[Thread-26,5,] count = 190728, Avg Get Time = 0.04553605134012835
Thread Thread[Thread-27,5,] count = 187245, Avg Get Time = 0.03894897060001602
Thread Thread[Thread-28,5,] count = 187020, Avg Get Time = 0.04590418137097636
Total Count = 1884042
Almost 2 million results and there was no cpu activity on the server. What this means is that Ehcache when used with Terracotta as a distributed cache, has the ability to also provide a local store. This is something that I’ve been meaning to incorporate into the current framework but I hadn’t figured out the best way to keep the local cache in sync with the server. There are instances where we will not always want to go over the network to retrieve cache data so this is a feature we will want to leverage.
Conclusion
There are other factors not included in the above results. At times restarting the Memcached server (which I did a lot) proved problematic as the client would experience errors where I was not sure of the actual cause. I was able to solve these issues by stopping the server and waiting for about a minute or two. Sometimes I had to restart the machine. Some of my tests not mentioned above proved too much for Ehcache as the garbage collector could not keep up and the process would run out of memory whereas Memcached had no problems. Overall, Memcached performed better and was less resource and cpi intensive. Even so, I believe that Ehcache is the better option for our product. The ability to have a local store for the most recently used objects per cache (our cache) would allow for less initial code changes. For example, code that accesses the same object repeatedly in a loop could stay that way without heavily impacting the application. We would want to rewrite such logic eventually but we wouldn’t be forced to do so up front. Also, in terms of monitoring, there seems to be better tools available for Ehcache. I’ve only glanced over them but another advantage is that the API for Ehcache allows exploration into the cache itself (i.e. a listing of all available keys), whereas I don’t believe the Memcached API has any such functionality.
Refactoring Techniques
What is Refactoring anyways?
Refactoring is the process of changing a computer program's source code without modifying its external functional behavior in order to improve some of the non-functional attributes of the software. It is a disciplined technique for restructuring an existing body of code, altering its internal structure without changing its external behaviour. Advantages include improved code readability and reduced complexity to improve the maintainability of the source code, as well as a more expressive internal architecture or object model to improve extensibility.
Its heart is a series of small behavior preserving transformations. Each transformation (called a 'refactoring') does little, but a sequence of transformations can produce a significant restructuring. Since each refactoring is small, it's less likely to go wrong. The system is also kept fully working after each small refactoring, reducing the chances that a system can get seriously broken during the restructuring. By continuously improving the design of code, we make it easier and easier to work with. If you get into the hygienic habit of refactoring continuously, you'll find that it is easier to extend and maintain code.
Motivation for Refactoring
Refactoring is usually motivated by noticing a code smell. For example the method at hand may be very long, or it may be a near duplicate of another nearby method. Once recognized, such problems can be addressed by refactoring the source code, or transforming it into a new form that behaves the same as before but that no longer "smells". For a long routine, extract one or more smaller subroutines. Or for duplicate routines, remove the duplication and utilize one shared function in their place. Failure to perform refactoring can result in accumulating technical debt. There are two general categories of benefits to the activity of refactoring.
Before refactoring a section of code, a solid set of automatic unit tests is needed. The tests should demonstrate in a few seconds that the behaviour of the module is correct. The process is then an iterative cycle of making a small program transformation, testing it to ensure correctness, and making another small transformation. If at any point a test fails, you undo your last small change and try again in a different way. Through many small steps the program moves from where it was to where you want it to be. Proponents of extreme programming and other agile methodologies describe this activity as an integral part of the software development cycle.
List of refactoring techniques
Here is a very incomplete list of code refactorings. A longer list can be found in Fowler's Refactoring book and on Fowler's Refactoring Website.
Techniques that allow for more abstraction
Writing Effective Designs
Overview
As the software development is maturing, the HLDs and LLDs are widely accepted as an integrated part of software development cycle, no matter what software development methodology we use. Even though the need of having a design is accepted and 30% to 40% of the total development effort is spent on design, it is rare to see effective designs that lay strong foundation for the application development. Very often they fail miserably in providing guidance and clarity for the development teams to start with and as a result the actual implementations are miles apart from the original design. In fact, in many cases the only useful purpose design serves is to complete the list of deliverables for the project for its closure and audits.
Writing effective design is one way to prevent such situations. This tutorial attempts to suggest a step by step approach to develop and deliver effective designs that shall not only be followed and respected by developer community but also play key role in development of stable and robust application.
What is design?
Before we get into the details about writing effective design, it is important that we have the same understanding about what the design is that we are referring to here. Here we are essentially talking about HLDs and LLDs for software development which is an essential part of software development and should ideally be available before the start of development face of the project.
What is an HLD?
Why we need HLD?
It is important for the management to be able to quantify effectiveness of a design. Following are a few signs that a good manager should always be looking at to find out if the designs are effective or not.
Characteristics of an ineffective HLD
Following are some signs for ineffective HLD
Following are some signs for ineffective LLD
Problems with HLD
It is equally important to for the delivery management to know if the design is effective as it is to know if it is not. It is management’s responsibility to not only improve the inefficiencies but also to encourage and carry forward and continue with the best practices and good design methodologies that are being followed.
Characteristics of an effective HLD
So far we have discussed the characteristics of an effective as well as an ineffective design and also the importance of the design and why do we need it. Now it is time that we should get our hands dirty with the real stuff “Writing effective design”. Here we shall discuss the prerequisites and the step by step approach to create effective HLDs and LLDs for a project.
Prerequisites for an effective HLD
Apart from all the prerequisites for HLD, the LLD designer should ensure that following artifacts are available before he/she starts with the LLD
Web Site Scalability
A classical large scale web site typically have multiple data centers in geographically distributed locations. Each data center will typically have the following tiers in its architecture
Content Delivery
Dynamic Content
There are 2 layers of dispatching for a Client who is making an HTTP request to reach the application server
DNS Resolution based on user proximity
This is concerned about designing an effective mechanism to communicate with the client, which is typically the browser making some HTTP call (maybe AJAX as well)
Designing the granularity of service call
Typical web transaction involves multiple steps. Session state need to be maintained across multiple interactions
Memory-based session state with Load balancer affinity
Remember the previous result can reuse them for future request can drastically reduce the workload of the system. But don't cache request which modifies the backend state.
Source : http://horicky.blogspot.in/2008/03/web-site-scalability.html
Database Scalability
Database is typically the last piece of the puzzle of the scalability problem. There are some common techniques to scale the DB tire
Indexing
Make sure appropriate indexes is built for fast access. Analyze the frequently-used queries and examine the query plan when it is executed (e.g. use "explain" for MySQL). Check whether appropriate index exist and being used.
Data De-normalization
Table join is an expensive operation and should be reduced as much as possible. One technique is to de-normalize the data such that certain information is repeated in different tables.
DB Replication
For typical web application where the read/write ratio is high, it will be useful to maintain multiple read-only replicas so that read access workload can be spread across. For example, in a 1 master/N slaves case, all update goes to master DB which send a change log to the replicas. However, there will be a time lag for replication.
Table Partitioning
You can partition vertically or horizontally.
Vertical partitioning is about putting different DB tables into different machines or moving some columns (rarely access attributes) to a different table. Of course, for query performance reason, tables that are joined together inside a query need to reside in the same DB.
Horizontally partitioning is about moving different rows within a table into a separated DB. For example, we can partition the rows according to user id. Locality of reference is very important, we should put the rows (from different tables) of the same user together in the same machine if these information will be access together.
Transaction Processing
Avoid mixing OLAP (query intensive) and OLTP (update intensive) operations within the same DB. In the OLTP system, avoid using long running database transaction and choose the isolation level appropriately. A typical technique is to use optimistic business transaction. Under this scheme, a long running business transaction is executed outside a database transaction. Data containing a version stamp is read outside the database trsnaction. When the user commits the business transaction, a database transaction is started at that time, the lastest version stamp of the corresponding records is re-read from the DB to make sure it is the same as the previous read (which means the data is not modified since the last read). Is so, the changes is pushed to the DB and transaction is commited (with the version stamp advanced). In case the version stamp is mismatched, the DB transaction as well as the business transaction is aborted.
Object / Relational Mapping
Although O/R mapping layer is useful to simplify persistent logic, it is usually not friendly to scalability. Consider the performance overhead carefully when deciding to use O/R mapping.
There are many tuning parameters in O/R mapping. Consider these ...
Scalable System Design
Building scalable system is becoming a hotter and hotter topic. Mainly because more and more people are using computer these days, both the transaction volume and their performance expectation has grown tremendously.
This one covers general considerations. I have another blogs with more specific coverage on DB scalability as well as Web site scalability.
General Principles
"Scalability" is not equivalent to "Raw Performance"
Common Techniques
Server Farm (real time access)
Scalable System Design Patterns
Load Balancer
In this model, there is a dispatcher that determines which worker instance will handle the request based on different policies. The application should best be "stateless" so any worker instance can handle the request.
Scatter and Gather
In this model, the dispatcher multicast the request to all workers of the pool. Each worker will compute a local result and send it back to the dispatcher, who will consolidate them into a single response and then send back to the client.
Result Cache
In this model, the dispatcher will first lookup if the request has been made before and try to find the previous result to return, in order to save the actual execution.
Shared Space
This model also known as "Blackboard"; all workers monitors information from the shared space and contributes partial knowledge back to the blackboard. The information is continuously enriched until a solution is reached.
Pipe and Filter
This model is also known as "Data Flow Programming"; all workers connected by pipes where data is flow across.
Map Reduce
The model is targeting batch jobs where disk I/O is the major bottleneck. It use a distributed file system so that disk I/O can be done in parallel.
Bulk Synchronous Parellel
This model is based on lock-step execution across all workers, coordinated by a master. Each worker repeat the following steps until the exit condition is reached, when there is no more active workers.
This model is based on an intelligent scheduler / orchestrator to schedule ready-to-run tasks (based on a dependency graph) across a clusters of dumb workers.
Source: http://horicky.blogspot.com/2010/10/scalable-system-design-patterns.html
Misconceptions About Software Architecture
References to architecture are everywhere: in every article, in every ad. And we take this word for granted. We all seem to understand what it means. But there isn't any wellaccepted definition of software architecture. Are we all understanding the same thing? We gladly accept that software architecture is the design, the structure, or the infrastructure. Many ideas are floating around concerning why and how you design or acquire an architecture and who does it. Here are some of the most common misconceptions about Software Architecture.
Architecture and design are the same thing
Architecture is design, but is not all of the design. Architecture is about making decisions on how the system will be built, it stops at the major abstractions, the major elements - the elements that are structurally important, but also those that have a more lasting impact on the performance, reliability, cost, and adaptability of the system. In constrast, design involves a lot more in order to take the design to implementation. In a word, architecture is the fundamental, architecturally-significant aspects of the design.
Architecture and infrastructure are the same thing
The infrastructure is an integral and important part of the architecture: It is the foundation. Choices of platform, operating systems, middleware, database, and so on, are major architectural choices. Architecture must include the application architecture plus the infrastructure architecture. There is far more to architecture than just the infrastructure. The architects have to consider the whole system, including all applications otherwise an overly narrow view of what architecture is may lead to a very nice infrastructure, but the wrong infrastructure for the problem at hand.
Architecture is just a structure
Architecture is more than just the structural organization of design elements, it also includes the description of how these elements collaborate, as well as why things are the way they are (the rationale). The architecture must describer how the architecture fits into the current business context and must address how it can be developed within the current development context.
Architecture is flat and one blueprint is enough
Architecture is a complex beast; it is many things to many different stakeholders. Using a single blueprint to represent architecture results in an unintelligible semantic mess. Like building architects who have floor plans, elevations, electrical cabling diagrams, and so on, we need multiple blueprints to address different concerns, and to express the separate but interdependent structures that exist in an architecture.
Architecture cannot be measured or validated
Architecture is not just a whiteboard exercise that results in a few interconnected boxes and is then labeled a high-level design. The development of the architecture involves design, implementation, testing, etc. There are many aspects you can validate by inspection, systematic analysis, simulation, or modelization.
Architecture is Science
If there is a spectrum between art (creative) and science (prescriptive), architecture is somewhere in-between. The architecture problem space is quite large. One of the reasons that architecture cannot yet be considered a science is that there are no good guidelines on how to traverse the solution space, "prune it", and then apply the selected solutions. Architecture is becoming an engineering discipline (it is steadily moving toward the science end of the spectrum). Nevertheless, it is not a strict science because if you put two architect in seperate rooms, give them just the requirements, each will (most probably) come up with a different architecture. However, if you constrain them with a set of architectural patterns, their results will be more similar.
Architecture is an art
Let's not fool ourselves. The artistic, creative part of software architecture is usually very small. Most of what architects do is copy solutions that they know worked in other similar circumstances, and assemble them in different forms and combinations, with modest incremental improvements. It is possible to describe an architectural process that has precise steps and prescribed artifacts, and that takes advantage of heuristics and patterns that are starting to be better understood.
Two powerful principles to improve the design
Coupling is usually contrasted with cohesion. Low coupling often correlates with high cohesion, and vice versa.
Low coupling is often a sign of a well-structured computer system and a good design, and when combined with high cohesion, supports the general goals of high readability and maintainability.
The goal of this case study is to show the benefits of low coupling and high cohesion, and how it can be implemented with Java. The case study consists of designing an application that accesses a file in order to get data, processes it, and prints the result to an output file.
Solution without design:
For this first solution the design is ignored and only one class named DataProcessor is used to:
- Get data from file.
- Processing data.
- Print result.
And the main method invokes the methods of this class.
I. Usability
This is the definition of the usability attributes that are required from the business. This addresses the complexity/simplicity of use.
II. Modifiability
This attribute defines the maintainability and modifiability of this feature/functionality. Considerations to the ease of making changes all the way to the availability of resources with the technical knowledge to support the feature/functionality are addressed here.
III. Performance
This attributes defines the performance qualities for this feature/functionality. Response times, processing times, etc. should be considered.
IV. Availability
This attribute defines what qualities pertain to how available this feature/functionality must be to users and other systems. Failover, recovery times, etc. would be considered here.
V. Security
This attribute defines the security qualities that define this feature/functionality. Elements as in protecting access, data, etc. should be considered.
VI. Testability
This attribute defines the quality attributes for testing this feature/function. Ease of testing – including Unit as well as QA are considered. Special attention to quality controls like test automation, heartbeats, dashboards that self test are also included in these considerations.
VII. Scalability
This attribute defines how this feature/functionality scales. Overall capacity should be considered at this point including future growth.
VIII. Portability
This attribute defines the portability of this functionality – Cross Plattform functionality as well as maintaining a light interdependence on common vendor functdionality (i.e.WebServers: JBoss vs Weblogic &/or WebSphere).
IX. Business Qualities
A. Time
This attribute defines the time constraints to deliver this functionality..
B. Cost (CBA)
This attribute defines the cost benefit of this functionality.
C. Market
This attribute defines the market segmentation of this functionality. Since we aren’t really managing to a Product Line, I’m OK with Omitting this in our definitions of architecture.
D. Integration
This attribute discusses the system integration of this functionality to other systems
E. Lifetime
This attribute defines the expected time this product is expected to exist, iterations that are expected to impact it, etc.
The 4 building blocks of Architecting Systems for Scale
A quick gloss on the building blocks:
- Load Balancing: Scalability & Redundancy. Horizontal scalability and redundancy are usually achieved via load balancing, the spreading of requests across multiple resources.
- Smart Clients. The client has a list of hosts and load balances across that list of hosts. Upside is simple for programmers. Downside is it's hard to update and change.
- Hardware Load Balancers. Targeted at larger companies, this is dedicated load balancing hardware. Upside is performance. Downside is cost and complexity.
- Software Load Balancers. The recommended approach, it's software that handles load balancing, health checks, etc.
- Caching. Make better use of resources you already have. Precalculate results for later use.
- Application Versus Database Caching. Databases caching is simple because the programmer doesn't have to do it. Application caching requires explicit integration into the application code.
- In Memory Caches. Performs best but you usually have more disk than RAM.
- Content Distribution Networks. Moves the burden of serving static resources from your application and moves into a specialized distributed caching service.
- Cache Invalidation. Caching is great but the problem is you have to practice safe cache invalidation.
- Off-Line Processing. Processing that doesn't happen in-line with a web requests. Reduces latency and/or handles batch processing.
- Message Queues. Work is queued to a cluster of agents to be processed in parallel.
- Scheduling Periodic Tasks. Triggers daily, hourly, or other regular system tasks.
- Map-Reduce. When your system becomes too large for ad hoc queries then move to using a specialized data processing infrastructure.
- Platform Layer. Disconnect application code from web servers, load balancers, and databases using a service level API. This makes it easier to add new resources, reuse infrastructure between projects, and scale a growing organization.
In this post I'll attempt to document some of the scalability architecture lessons learned while working on systems at Yahoo! and Digg.
I've attempted to maintain a color convention for diagrams in this post:
- green represents an external request from an external client (an HTTP request from a browser, etc),
- blue represents your code running in some container (a Django app running on mod_wsgi, a Python script listening to RabbitMQ, etc), and
- red represents a piece of infrastructure (MySQL, Redis, RabbitMQ, etc).
Load Balancing: Scalability & Redundancy
The ideal system increases capacity linearly with adding hardware. In such a system, if you have one machine and add another, your capacity would double. If you had three and you add another, your capacity would increase by 33%. Let's call this horizontal scalability.
On the failure side, an ideal system isn't disrupted by the loss of a server. Losing a server should simply decrease system capacity by the same amount it increased overall capacity when it was added. Let's call this redundancy.
Both horizontal scalability and redundancy are usually achieved via load balancing.
(This article won't address vertical scalability, as it is usually an undesirable property for a large system, as there is inevitably a point where it becomes cheaper to add capacity in the form on additional machines rather than additional resources of one machine, and redundancy and vertical scaling can be at odds with one-another.)
Load balancing is the process of spreading requests across multiple resources according to some metric (random, round-robin, random with weighting for machine capacity, etc) and their current status (available for requests, not responding, elevated error rate, etc).
Load needs to be balanced between user requests and your web servers, but must also be balanced at every stage to achieve full scalability and redundancy for your system. A moderately large system may balance load at three layers: from the
- user to your web servers, from your
- web servers to an internal platform layer, and from your
- internal platform layer to your database.
Smart Clients
Adding load-balancing functionality into your database (cache, service, etc) client is usually an attractive solution for the developer. Is it attractive because it is the simplest solution? Usually, no. Is it seductive because it is the most robust? Sadly, no. Is it alluring because it'll be easy to reuse? Tragically, no.
Developers lean towards smart clients because they are developers, and so they are used to writing software to solve their problems, and smart clients are software.
With that caveat in mind, what is a smart client? It is a client which takes a pool of service hosts and balances load across them, detects downed hosts and avoids sending requests their way (they also have to detect recovered hosts, deal with adding new hosts, etc, making them fun to get working decently and a terror to get working correctly).
Hardware Load Balancers
The most expensive--but very high performance--solution to load balancing is to buy a dedicated hardware load balancer (something like a Citrix NetScaler). While they can solve a remarkable range of problems, hardware solutions are remarkably expensive, and they are also "non-trivial" to configure.
As such, generally even large companies with substantial budgets will often avoid using dedicated hardware for all their load-balancing needs; instead they use them only as the first point of contact from user requests to their infrastructure, and use other mechanisms (smart clients or the hybrid approach discussed in the next section) for load-balancing for traffic within their network.
Software Load Balancers
If you want to avoid the pain of creating a smart client, and purchasing dedicated hardware is excessive, then the universe has been kind enough to provide a hybrid approach: software load-balancers.
HAProxy is a great example of this approach. It runs locally on each of your boxes, and each service you want to load-balance has a locally bound port. For example, you might have your platform machines accessible via localhost:9000, your database read-pool at localhost:9001 and your database write-pool at localhost:9002. HAProxy manages healthchecks and will remove and return machines to those pools according to your configuration, as well as balancing across all the machines in those pools as well.
For most systems, I'd recommend starting with a software load balancer and moving to smart clients or hardware load balancing only with deliberate need.
Caching
Load balancing helps you scale horizontally across an ever-increasing number of servers, but caching will enable you to make vastly better use of the resources you already have, as well as making otherwise unattainable product requirements feasible.
Caching consists of: precalculating results (e.g. the number of visits from each referring domain for the previous day), pre-generating expensive indexes (e.g. suggested stories based on a user's click history), and storing copies of frequently accessed data in a faster backend (e.g. Memcache instead of PostgreSQL.
In practice, caching is important earlier in the development process than load-balancing, and starting with a consistent caching strategy will save you time later on. It also ensures you don't optimize access patterns which can't be replicated with your caching mechanism or access patterns where performance becomes unimportant after the addition of caching (I've found that many heavily optimized Cassandra applications are a challenge to cleanly add caching to if/when the database's caching strategy can't be applied to your access patterns, as the datamodel is generally inconsistent between the Cassandra and your cache).
Application Versus Database Caching
There are two primary approaches to caching: application caching and database caching (most systems rely heavily on both).
Application caching requires explicit integration in the application code itself. Usually it will check if a value is in the cache; if not, retrieve the value from the database; then write that value into the cache (this value is especially common if you are using a cache which observes the least recently used caching algorithm). The code typically looks like (specifically this is a read-through cache, as it reads the value from the database into the cache if it is missing from the cache):
key = "user.%s" % user_id
user_blob = memcache.get(key)
if user_blob is None: user = mysql.query("SELECT * FROM users WHERE user_id=\"%s\"", user_id)
if user:
memcache.set(key, json.dumps(user))
return user
else:
return json.loads(user_blob)
The other side of the coin is database caching.
When you flip your database on, you're going to get some level of default configuration which will provide some degree of caching and performance. Those initial settings will be optimized for a generic usecase, and by tweaking them to your system's access patterns you can generally squeeze a great deal of performance improvement.
The beauty of database caching is that your application code gets faster "for free", and a talented DBA or operational engineer can uncover quite a bit of performance without your code changing a whit (my colleague Rob Coli spent some time recently optimizing our configuration for Cassandra row caches, and was succcessful to the extent that he spent a week harassing us with graphs showing the I/O load dropping dramatically and request latencies improving substantially as well).
In Memory Caches
The most potent--in terms of raw performance--caches you'll encounter are those which store their entire set of data in memory. Memcached andRedis are both examples of in-memory caches (caveat: Redis can be configured to store some data to disk). This is because accesses to RAM are orders of magnitudefaster than those to disk.
On the other hand, you'll generally have far less RAM available than disk space, so you'll need a strategy for only keeping the hot subset of your data in your memory cache. The most straightforward strategy is least recently used, and is employed by Memcache (and Redis as of 2.2 can be configured to employ it as well). LRU works by evicting less commonly used data in preference of more frequently used data, and is almost always an appropriate caching strategy.
Content Distribution Networks
A particular kind of cache (some might argue with this usage of the term, but I find it fitting) which comes into play for sites serving large amounts of static media is the content distribution network.
CDNs take the burden of serving static media off of your application servers (which are typically optimzed for serving dynamic pages rather than static media), and provide geographic distribution. Overall, your static assets will load more quickly and with less strain on your servers (but a new strain of business expense).
In a typical CDN setup, a request will first ask your CDN for a piece of static media, the CDN will serve that content if it has it locally available (HTTP headers are used for configuring how the CDN caches a given piece of content). If it isn't available, the CDN will query your servers for the file and then cache it locally and serve it to the requesting user (in this configuration they are acting as a read-through cache).
If your site isn't yet large enough to merit its own CDN, you can ease a future transition by serving your static media off a separate subdomain (e.g. static.example.com) using a lightweight HTTP server like Nginx, and cutover the DNS from your servers to a CDN at a later date.
Cache Invalidation
While caching is fantastic, it does require you to maintain consistency between your caches and the source of truth (i.e. your database), at risk of truly bizarre applicaiton behavior.
Solving this problem is known as cache invalidation.
If you're dealing with a single datacenter, it tends to be a straightforward problem, but it's easy to introduce errors if you have multiple codepaths writing to your database and cache (which is almost always going to happen if you don't go into writing the application with a caching strategy already in mind). At a high level, the solution is: each time a value changes, write the new value into the cache (this is called a write-through cache) or simply delete the current value from the cache and allow a read-through cache to populate it later (choosing between read and write through caches depends on your application's details, but generally I prefer write-through caches as they reduce likelihood of a stampede on your backend database).
Invalidation becomes meaningfully more challenging for scenarios involving fuzzy queries (e.g if you are trying to add application level caching in-front of a full-text search engine likeSOLR), or modifications to unknown number of elements (e.g. deleting all objects created more than a week ago).
In those scenarios you have to consider relying fully on database caching, adding aggressive expirations to the cached data, or reworking your application's logic to avoid the issue (e.g. instead of DELETE FROM a WHERE..., retrieve all the items which match the criteria, invalidate the corresponding cache rows and then delete the rows by their primary key explicitly).
Off-Line Processing
As a system grows more complex, it is almost always necessary to perform processing which can't be performed in-line with a client's request either because it is creates unacceptable latency (e.g. you want to want to propagate a user's action across a social graph) or it because it needs to occur periodically (e.g. want to create daily rollups of analytics).
Message Queues
For processing you'd like to perform inline with a request but is too slow, the easiest solution is to create a message queue (for example, RabbitMQ). Message queues allow your web applications to quickly publish messages to the queue, and have other consumers processes perform the processing outside the scope and timeline of the client request.
Dividing work between off-line work handled by a consumer and in-line work done by the web application depends entirely on the interface you are exposing to your users. Generally you'll either:
- perform almost no work in the consumer (merely scheduling a task) and inform your user that the task will occur offline, usually with a polling mechanism to update the interface once the task is complete (for example, provisioning a new VM on Slicehost follows this pattern), or
- perform enough work in-line to make it appear to the user that the task has completed, and tie up hanging ends afterwards (posting a message on Twitter or Facebook likely follow this pattern by updating the tweet/message in your timeline but updating your followers' timelines out of band; it's simple isn't feasible to update all the followers for a Scobleizer in real-time).
Scheduling Periodic Tasks
Almost all large systems require daily or hourly tasks, but unfortunately this seems to still be a problem waiting for a widely accepted solution which easily supports redundancy. In the meantime you're probably still stuck with cron, but you could use the cronjobs to publish messages to a consumer, which would mean that the cron machine is only responsible for scheduling rather than needing to perform all the processing.
Does anyone know of recognized tools which solve this problem? I've seen many homebrew systems, but nothing clean and reusable. Sure, you can store the cronjobs in a Puppetconfig for a machine, which makes recovering from losing that machine easy, but it would still require a manual recovery, which is probably acceptable but not quite perfect.
Map-Reduce
If your large scale application is dealing with a large quantity of data, at some point you're likely to add support for map-reduce, probably using Hadoop, and maybeHive or HBase.
Adding a map-reduce layer makes it possible to perform data and/or processing intensive operations in a reasonable amount of time. You might use it for calculating suggested users in a social graph, or for generating analytics reports.
For sufficiently small systems you can often get away with adhoc queries on a SQL database, but that approach may not scale up trivially once the quantity of data stored or write-load requires sharding your database, and will usually require dedicated slaves for the purpose of performing these queries (at which point, maybe you'd rather use a system designed for analyzing large quantities of data, rather than fighting your database).
Platform Layer
Most applications start out with a web application communicating directly with a database. This approach tends to be sufficient for most applications, but there are some compelling reasons for adding a platform layer, such that your web applications communicate with a platform layer which in turn communicates with your databases.
First, separating the platform and web application allow you to scale the pieces independently. If you add a new API, you can add platform servers without adding unnecessary capacity for your web application tier. (Generally, specializing your servers' role opens up an additional level of configuration optimization which isn't available for general purpose machines; your database machine will usually have a high I/O load and will benefit from a solid-state drive, but your well-configured application server probably isn't reading from disk at all during normal operation, but might benefit from more CPU.)
Second, adding a platform layer can be a way to reuse your infrastructure for multiple products or interfaces (a web application, an API, an iPhone app, etc) without writing too much redundant boilerplate code for dealing with caches, databases, etc.
Third, a sometimes underappreciated aspect of platform layers is that they make it easier to scale an organization. At their best, a platform exposes a crisp product-agnostic interface which masks implementation details. If done well, this allows multiple independent teams to develop utilizing the platform's capabilities, as well as another team implementing/optimizing the platform itself.
I had intended to go into moderate detail on handling multiple data-centers, but that topic truly deserves its own post, so I'll only mention that cache invalidation and data replication/consistency become rather interesting problems at that stage.
I'm sure I've made some controversial statements in this post, which I hope the dear reader will argue with such that we can both learn a bit. Thanks for reading!
Source: http://lethain.com/introduction-to-architecting-systems-for-scale/
The 7 stages of scaling web apps
Good presentation of the stages a typical successful website goes through:
- Stage 1 - The Beginning: Simple architecture, low complexity. no redundancy. Firewall, load balancer, a pair of web servers, database server, and internal storage.
- Stage 2 - More of the same, just bigger.
- Stage 3 - The Pain Begins: publicity hits. Use reverse proxy, cache static content, load balancers, more databases, re-coding.
- Stage 4 - The Pain Intensifies: caching with memcached, writes overload and replication takes too long, start database partitioning, shared storage makes sense for content, significant re-architecting for DB.
- Stage 5 - This Really Hurts!: rethink entire application, partition on geography user ID, etc, create user clusters, using hashing scheme for locating which user belongs to which cluster.
- Stage 6 - Getting a little less painful: scalable application and database architecture, acceptable performance, starting to add ne features again, optimizing some code, still growing but manageable.
- Stage 7 - Entering the unknown: where are the remaining bottlenecks (power, space, bandwidth, CDN, firewall, load balancer, storage, people, process, database), all eggs in one basked (single datacenter, single instance of data).
Prime directive of scaling: Think Horizontally at every point in your architecture, not just at the web tier. You may not agree with everything, but there's a lot of useful advice. Here's a summary:
- Benchmarking
- Vertical scaling sucks.
- Horizontal scaling rocks.
- Run many application servers
- Don't keep state in the app server
- Be stateless
- Optimization is necessary, but is different than scalability.
- Cache things you hit all the time.
- Measure, don't assume, check.
- Make pages static.
- Caching is a trade-off.
- Cache full pages.
- Cache partial pages.
- Cache complex data.
- MySQL query cache is flushed on update.
- Cache invalidation is hard.
- Replication scales reads, not writes.
- Partition to scale writes. 96% of applications can skip this step.
- Master-master setup facilitates on-line schema changes.
- Create summary tables and summary databases rather than do COUNT and GROUP-BY at runtime.
- Make code idempotent. If it fails you should just be able to run it again.
- Load data asynchronously. Aggregate updates into batches.
- Move processing to application and out of the database as much as possible.
- Stored procedures are dangerous.
- Add more memory.
- Enable query logging and take a look at what your app is doing.
- Run different MySQL instances for different work loads.
- Config tuning helps, query tuning works.
- Reconsider persistent DB connections.
- Don't overwork the database. It's hard to scale.
- Work in parallel.
- Use a job queuing system.
- Log http requests.
- Use light processes for light tasks.
- Build on APIs internally. Clean loosely coupled APIs are easy to scale.
- Don't incur technical debt.
- Automatically handle failures.
- Make services that always work.
- Load balancing is the key to horizontal scaling.
- Redundancy is not load-balancing. Always have n+1 capacity.
- Plan for disasters.
- Make backups.
- Keep software deployments easy.
- Have everything scripted.
- Monitor everything. Graph everything.
- Run one service per server.
- Don't ever swap memory for disk.
- Run memcached if you have extra memory.
- Use memory to save CPU or IO. Balance memory vs CPU vs IO.
- Netboot your application servers.
- There's lot of good slides on what to graph.
- Use a CDN.
- Use YSlow to find client side problems.
I’ve spent the last five years implementing and thinking about service oriented architectures. One of the core benefits of a service oriented approach is the promise of greatly enhanced scalability and redundancy. But to realise these benefits we have to write our services to be ‘scalable’. What does this mean?
There are two fundamental ways we can scale software: 'Vertically' or 'horizontally'.
- Vertical Scaling addresses the scalability of a single instance of the service. A simple way to scale most software is simply to run it on a more powerful machine; one with a faster processor or more memory. We can also look for performance improvements in the way we write the code itself. An excellent example of company using this approach is LMAX. However, there are many drawbacks to the vertical scaling approach. Firstly the costs are rarely linear; ever more powerful hardware tends to be exponentially more expensive and the costs (and constraints) of building sophisticated performance optimised software are also considerable. Indeed premature performance optimisation often leads to overly complex software that's hard to reason about and therefore more prone to defects and high maintenance costs. Most importantly, vertical scaling does not address redundantcy; vertically scaling an application just turns a small single point of failure into a large single point of failure.
- Horizontal Scaling. Here we run multiple instances of the application rather than focussing on the performance of a single instance. This has the advantage of being linearly scalable; rather than buying a bigger, more expensive box, we just buy more copies of the same cheap box. With the right architectural design, this approach can scale massively. Indeed it's the approach taken by almost all of largest internet scale companies: Facebook, Google, Twitter etc.. Horizontal Scaling also introduces redundancy; the loss of a single node need not impact the system as a whole. For these reasons, horizontal scaling is the preferred approach to building scalable, redundant systems.
- Stateless. Any services that stores state across an interaction with another service is hard to scale. For example, a web service that stores in-memory session state between requests requires a sophisticated session-aware load balancer. A stateless service, by contrast, only requires simple round-robin load balancing. For a web application (or service) you should avoid using session state or any static or application level variables.
- Coarse Grained API. To be stateless, a service should expose an API that exposes operations as a single interaction. A chatty API, where one sets up some data, asks for some transition, and then reads off some results, implies statefulness by its design. The service would need to identify a session and then maintain information about that session between successive calls. Instead a single call, or message, to the service should encapsulate all the information that the service requires to complete the operation.
- Idempotent. Much scalable infrastructure is a trade-off between competing constraints. Delivery guarantees are one of these. For various reasons it's is far simpler to guarantee 'at least once' delivery than 'exactly once'. If you can make your software tolerant of multiple deliveries of the same message it will be easier to scale.
- Embrace Failure. Arrays of services are redundant if the system as a whole can survive the loss of a single node. You should design your services and infrastructure to expect and survive failure. Consider implementing a Chaos Monkey that randomly kills processes. If you start by expecting your services to fail, you'll be prepared when they inevitably do.
- Avoid instance specific configuration. A scalable service should be designed in such a way that it doesn't need to know about other instances of itself, or have to identify itself as a specific instance. I shouldn't need to have to configure one instance any differently than another. This would include communication mechanisms that require messages to be addressed to a specific instance of the service, or some non-convention based way that the service was required to identify itself. Instead we should rely on infrastructure (load-balancers, pub-sub messaging etc.) to manage the communication between arrays of services.
- Simple automated deployment. Have a service that can scale is no advantage if we can't deploy it when we are close to capacity. A scalable system must have automated processes to deploy new instances of services as the need arises.
- Monitoring. We need to know when services are close to capacity so that we can add additional service instances. Monitoring is usually an infrastructure concern; we should be monitoring CPU, network, and memory usage and have alerts in place to warn us when these pass certain trigger points. Sometimes it's worth introducing application specific alerts when some internal trigger is reached, such as the number of items in an in-memory queue, for example.
- KISS - Keep It Small and Simple. This is good advice for any software project, but is especially pertinent to building scalable resilient systems. Large monolithic codebases are hard to reason about, hard to monitor, and hard to scale. Building your system out of many small pieces makes it easy to address those pieces independently. Design your system so that each service has only one purpose and is decoupled from the operations of other services. Have your services communicate using non-proprietary open standards to avoid vendor lock-in and allow for a heterogeneous platform. JSON over HTTP, for example, is an excellent choice for intra-service communication. Every platform has HTTP and JSON libraries and there is abundant off-the-shelf infrastructure (proxies, load-balancers, caches) that can be used to help your system scale.
Is Hibernate the best choice?
Is Hibernate the best choice? Or is the technical marketing of other ORM vendors lacking? Recently Jonathan Lehr posed a question on his blog: "Is Hibernate the best choice?", and this lead me to ask the same question.
Although, I tend to use Hibernate as my first choice, it would be nice to see some head to head comparisons of Hibernate vs. TopLink (pros and cons), Hibernate vs. OpenJPA, Hibernate vs. Cayenne, etc. Searching around finds that many of the comparison are pretty old and not very detailed or compelling.
Having used other ORM frameworks, I found that when something goes wrong with Hibernate, you can usually google and find an answer, and there are many books on Hibernate. In my experience, the other frameworks seemed to be a less well-worn path and it is harder to find answers to even common problems. This is not to say that Hibernate is better, but that it is a lot more popular. In the end, I use Hibernate because my clients use it, if my clients switched to TopLink or OpenJPA, then I would use them as well.
So this begs the question, if Hibernate works for you, you just might have something else to do, like implementing a client solution that makes your client money, than to try several other ORM frameworks. How much time should someone spend learning a new ORM framework (new to them anyway)?
Don't get this wrong, trying out new ORM frameworks is fine. If there is a large IT/developer organization, and you have a certain selection criteria like integrating with legacy databases, conformance to JPA specification, ability to hire new developers, easy of use, etc. then by all means having someone create a few prototypes and/or proofs of concepts and try out a few ORM frameworks is great. There is often good ROI in this type of testing. Perhaps share your findings with the rest of us.
However, it seems if you are a vendor of a JPA solution, you could start by pointing out how your product differs from Hibernate. Like it or not, Hibernate dominates the mind-share of developers. If you can't prove your ORM frameworks has compelling reasons for switching, why should developers spend their time evaluating your product?
Now let me boil things down to brass tacks, it seems vendors of the ORMs should write white-papers, articles, blogs, and such to highlight the advantages of their ORM framework versus Hibernate. Logic dictates that if you have a product and there is a competing product that dominates the market that you might want to highlight what differentiates your product from the dominate one.
As a test, let's go to different vendor sites and see if they have comparisons of their ORM framework vs. the 800 pound gorilla, Hibernate.
So first let's go to Oracle TopLink website, you would expect since Hibernate has such a huge adoption rate in the industry that Oracle would want to point out why TopLink is better like a nice white-paper perhaps featured prominently on their TopLink site (see graph).
After hunting around a bit this entry appeared in the TopLink Essentials FAQ, Why should TopLink Essentials be used instead of JBoss(TM) Hibernate?
The two main points that seemed intriguing were as follows:
"Customers with any degree of complexity in the domain model or relational schemas, most notably where changing the schema is not an option, will benefit from the flexibility and proven nature of TopLink."
NOTE: At times mapping Hibernate to legacy systems can be challenging. How is TopLink better at this? Are there articles or white-papers, etc. that attempt to prove that TopLink is better at legacy integration? (I find that many developers are not aware of all of the features that Hibernate provides for legacy mapping.)
"As the reference implementation of JPA TopLink offers the first certified implementation of this new standard. as well as providing some useful value-add functionality. Going forward this open source project will continue to innovate based on contributions from Oracle, Sun, and others."
NOTE: This is compelling to me since I now use the JPA interface to Hibernate whenever I can.
Now I did not find the arguments in the FAQ particularly compelling or at all detailed. Sadly, you can find more compelling arguments in some of the TopLink public forums and random blogs. However, none so compelling that I feel the sudden need to switch.
Now on to the BEA site to look at dear KODO. I have always heard good things about KODO. Sadly, I found the BEA KODO site to be very out of date. It mentions a 2005 award for KODO as the lead news item. It also mentions that OpenJPA is in incubation, it has been out for a while. Even the FAQ, which did mention Hibernate, merely mentions that Hibernate is not EJB3 (seems it should say Hibernate is not JPA). This site really seems out of date and like the TopLink site mosty ignores the elephant in the room (see graph).
Well, let's look at the Apache OpenJPA site, as KODO's DNA may live at Apache long after Oracle decides on a single JPA solutions and likely leaves KODO to rot on the vine. Searching through the main site, FAQ, OpenJPA documentation, etc., I find no mention of Hibernate. Now this is an open source project so one would likely expect to see no marketing angle per se. But, you might expect that a project recognize that many would not be able to use this project without first justifying their pick against picking Hibernate (OpenJPA barely appears at all on job graphs). How many IT/development managers will feel comfortable with this choice without some explanation?
Now on to the next ORM framework site, Cayenne. No mention of Hibernate vs. Cayenne (but I know I have read articles on this). Seems like there might be some compelling ease-of-use arguments for Cayenne vs. Hibernate but they choose not to compare them. (Cayenne barely appears at all on job graphs)
Now back to Jonathan Lehr blog, Jonathan states that he feels TopLink and Cayenne are better choices than Hibernate and cites his reasons for these choices. There is a long discussion on the pros and cons of each in the comment section. I'd love to see more discussion, and I'd love to see some viable alternatives to Hibernate, but feel that no vendor or open source project does a real good job of pointing out the differences and possible limitations of Hibernate. If the vendors and project owners choose not to make their case, it makes it very difficult for the rank and file developers to make their case.
Perhaps one reason Hibernate is so dominate is because competing projects are so bad at technical marketing. Not one project I looked at mentions Hibernate on their front page. I could not find a decent comparison of features (to Hibernate's) on any of the ORM sites.
Has anyone done a comparison of Hibernate and OpenJPA, TopLink Essentials, Cayenne that compares ease-of-use, caching, tool support, legacy integration, etc.? Perhaps such an internal report was used to decide which ORM tool to pick. If so, what were the results?
If you use TopLink, OpenJPA, Cayenne instead of Hibernate, why?
Were you hoping that JPA would level the playing field and there would be more competition?
Cassandra Adds Hadoop MapReduce
Today the Cassandra project announced its first new release since becoming a Top-Level Project at Apache. Don't let the low version number fool you. Cassandra 0.6 is one of the most mature NoSQL distributed data stores in the open source market. It was heavily developed by Facebook before it was open sourced in August 2008. Currently Cassandra is being used by four of the largest social media sites in the world: Facebook, Digg, Reddit, and Twitter.
One of the primary new features in Cassandra 0.6 is support for Apache Hadoop. This is a major upgrade for Cassandra, giving it even more "big data" capabilities. The new feature will allow Cassandra to run analytics against its own data using Hadoop's reliable MapReduce framework.
Cassandra 0.6 simplifies its architecture with a new integrated caching row. With the implementation of this new feature, Cassandra no longer needs a separate caching layer. Along with the simplified architecture, Cassandra 0.6 also features a performance boost. The distributed data store can already process thousands of writes per second, and this version's enhancements builds on that number.
"Apache Cassandra 0.6 is 30% faster across the board, building on our already-impressive speed," said Jonathan Ellis, Apache Cassandra Project Management Committee Chair in the press release. "It achieves scale-out without making the kind of design compromises that result in operations teams getting paged at 2 AM." The Storage Team Technical Lead at Twitter, Ryan King, explained Twitter's reasons for using Cassandra: "At Twitter, we're deploying Cassandra to tackle scalability, flexibility and operability issues in a way that's more highly available and cost effective than our current systems."
One of Cassandra's best known features is its lack of any single point of failure. The data store's distributed system smoothly replaces any node that goes down with a new node. The system also has the flexibility to be tuned for more consistency or more availability.
The previous version of Cassandra (0.5) added load balancing and significantly improved bootstrap and concurrency. New tools were also added, including JSON-based data import and export, new JMX metrics, and an improved command line interface. “It's fantastic seeing the Project's community at the ASF grow to match the promise of the technology," said Ellis.
You can download Cassandra 0.6 now on the project's website. For more info on Cassandra, check out "4 Months with Cassandra, a love story."
Cache selection(POC) for one of my product
Introduction
The purpose of this document is to define a new cache implementation for one of my product. This new cache implementation is proposed to improve the scalability, manageability, and distribution of cache items in the my Platform.
Current Cache Issues
The following sections define the most critical problems with the current cache implementation of which the proposed new cache solution will address.
Multiple Cache Copies
The current cache implementation is designed such that a complete copy of the cache exists on every application server in which our Product is deployed. With this design, as clients and data are added to the cache in an instance of a our platform product the amount of memory taken up by the cache increases linearly with the amount of data added to it. The result of this increase in memory per client and data item added takes away from application server memory thus limiting the overall scalability of the platform. As memory increases due to new clients and data, adding application server machines to handle increased load has less and less of an effect because of the amount of memory taken away from the application itself by the cache.
As clients (and products) are added to the system the amount of memory allocated by the cache increases until adding machines to the cluster to handle performance load (CPU) issues has no effect due to memory constraints and a new separate application cluster would need to be created. Once the client/application threshold is reached in terms of memory, the footprint of all the machines in the cluster will look like the 10 client footprint .
Cache Reload Time
Another side effect of having an instance of the cache in each application server is if an application server must be restarted or shut down for any reason the data in the cache is cleared. When the application is restarted the cached data must be reloaded from the database. The time to reload the cache can be considerable and will only increase as we add clients and data to the cache over time. The time it takes to reload the cache directly increases the amount of downtime required to make code or other modifications requiring a restart of the system. The reloading of the cache is especially time consuming in the current cache implementation since most of the items in the cache are loaded at startup instead of as-needed.
Cache Item Update Complexity
The current cache implementation also has the added complexity of updating other application servers participating in a our Product cluster when a cached item is modified. For example, if a cache item is modified in Machine 1 of a cluster of 5 Machines then the item must also be sent to the modified item must also be updated in caches of the remaining 4 machines. Up to this time, this distributed cache process has been problematic during restarts and there is no 100pct certainty that modified cache items are distributed properly to the other machines participating in the cluster.
Proposed Solution to the Current Cache Issues
In order to solve the issues of the current cache implementation, a distributed-hash based cache solution is proposed. In a distributed-hash based cache (DHBC) implementation the cache is extracted from the application servers and resides in a separate cluster of cache machines. The DHCB cluster acts as a single very large cache limited only by the total memory of all the machines participating in the cluster. So for example if there are four machines in the DHBC cluster each with 4GB of RAM then the DHBC cluster capacity will be 16GB minus whatever memory the operating system and required apps need.
The distributed-hash algorithm determines which cache cluster machine in which to connect. Once an item is added to the cache by a member of the application server cluster, the item is available to all members of the application server cluster without having to distribute it.
Cache Items in a DHBC
A cache item in a DHBC cluster exists only once in the cache. When an item is requested from the DHBC the distributed hash algorithm determines on which machine the cache item resides and returns the appropriate item if it exists. The distributed hash algorithm also determines on which machine to put a new cache item. As new machines are added to the DHBC cluster the distributed hash algorithm automatically adjusts itself and uses the new machine as part of the overall cache.
If a machine participating in a DHBC cluster goes down, the distributed hash algorithm is designed to adapt to the fact that a participating machine is down. Any new cached items will be added to the remaining servers and items that were in the downed server must be added again to the distributed cache.
Load on Demand Additionally, in order to be as fault-tolerant as possible the cache strategy must be changed from a “load once at startup and update” strategy to a “load on demand” strategy. If a “load on demand” strategy is employed by the application programmers then the application itself will be insulated from issues that may arise if any machines participating in the DHBC cluster fail. A “load on demand” strategy means if item already exists in the cache when requested then return it, otherwise add it to the cache so new requests for the cached item will have it. In this case, if a machine participating in the DHBC cluster fails and a cached item is not returned then simply add it again to the cache. The only issue will be a slight performance hit when the cached items in the failed machine are reloaded into the cache as they are requested.
Cache Updates
Cache updates are much less complex in a DHBC implementation than the existing cache solution. If an item is added to the cache or replaced with a new value the item is automatically available to any application that requests it. The item does not need to be distributed to other servers in the cluster (application or otherwise).
Effects on Application Reload Time
Since the items in a DHBC cluster do not reside within the application server, the application servers can be stopped and restarted without affecting the cache. So, if an application server needs to be restarted because of a code change or other maintenance the application server can be started much more quickly since the cache does not need to be reloaded. Additionally, the newly started server will have access to any new items that were added or updated to the cache while the server application server was down for maintenance.
Implementing the DHBC
In order to implement the DHBC it is required to have a DHBC implementation itself and a client from which to access the HDBC cluster. For this purpose it is recommended to use the Linux based memcached implementation. Note that the client itself is available in most languages and platforms and does need to run on a Linux platform.
Memcached
Memcached is commonly available for most Linux distributions and has been used extensively by Facebook and many other websites as well as the MySQL database and Hibernate database library to provide scalable easy to use cache implementations. Memcached and the clients that use it are all open sourced so we can acquire the source code and modify it if necessary.
Information on memcached can be acquired from the following web site:
http://www.danga.com/memcached/
The list of memcached clients that can be used for each programming language is found here:
http://code.google.com/p/memcached/wiki/Clients
Sample code for each of the clients can be acquired from the above web site. However, for initial testing I have used the spymemcached client listed on the above web site and some sample code of my own for it be needed.
Hash Key The most important part of implementing the DHCB will be the choice of hash key. The hash key is used to uniquely identify a hash item in the DHCB. I recommend a key like the following:
< DISCRIMINATOR>.<APPLICATION>.<CLIENT>.<VALUE_KEY>
Where DISCRIMINATOR can be anything desired such as “TestEnvironment” or another grouping, APPLICATION is an application identifier such as “OurProduct”, CLIENT is either “ANY_CLIENT” or a specific client such as “WalMart”, and the VALUE_KEY can be anything appropriate.
For example if the DISCRIMINATOR is“JeffsTests”, the APPLICATION is “OurProduct”, the value is shared across clients, and the VALUE_KEY is page.login.firstNamethen the key would be “JeffsTests.OurProduct.ANY_CLIENT.page.login.userName”. The example key is for clarity but the key components can be abbreviated and shortened.
The <DISCRIMINATOR> in the key strategy allows multiple installations (or developers or testers or environments) to use the same memcached instance without interfering with each other.
This key strategy should be flexible enough for our present and future needs but can be enhanced as better ideas arise.
Memcached Environment
There is a test environment with the memcached server installed and already set up on two Ubuntu Linux servers. The IP addresses, user names, and passwords are available on request. It is necessary to download and install an SSH client to connect to and use the Linux servers from a windows desktop. A reasonable choice is the freely available putty (http://www.chiark.greenend.org.uk/~sgtatham/putty/) SSH client.
Implementation in Existing product
To implement memcached in the existing product it is recommended to create a switch value that can switch between memcached implementation and the existing design until developers, hosting, and others get used to working with memcached. The existing design can then be phased out whenever is appropriate.
In addition to the switch above, the cache strategy in the existing product should be changed to a “load on demand” strategy as defined in the Load on Demand section of this document. If, after implementing the“load on demand” strategy it is still required or desired to load very frequently and/or first used information into the cache then a routine to seed the cache by simply requesting keys for those items can be put in place.
It is required to implement an appropriate cache key strategy similarly to the strategy defined in the Hash Key section of this document.
Tools and utilities should also be created to check the number of keys, memory allocated, and other statistical information about the cache. The statistical tools should be compatible with the SiteMonitor program hosting uses to check for failures to ensure any production issues are quickly identified.
Additionally, routines should be created to allow for selective deletion and arbitrary viewing of items in the cache for maintenance reasons such as removing clients and debugging.
Testing
Since the cache implementation touches virtually every component of the our Product and related applications, once implementation in our product is completed a full functional regression test of the Applications making use of the cache needs to be performed. Additionally, the usual load tests should be performed as well to address any performance concerns.
Deployment
It is recommended that there be at least three memcached environments be deployed after implementation is complete. The three environments are Production, Staging, and QA/Development. QA and Development can make use of the< DISCRIMINATOR> value in the key to isolate key items from development and testing efforts. Another environment can be created if it is not desired to have QA and development using the same machines.
There should be at least two servers in the memcached cluster to allow for fault tolerance, complete testing, and scalability. In the production environment I recommend at least three servers to make sure that if a machine goes down there is ample room in the cluster to handle the cached items in the failed server. For example, if it takes 4GB to cache all the required data I would recommend three machines with at least 2GB of memory so the remaining clusters can handle the cache requirements without the third machine. It is also important to make sure the network connecting the application server machines and the DHBC cluster is a fast and fault tolerant as possible to avoid bottlenecks and performance issues.
More Possibilities
In addition to replacing the existing cache mechanism used by our product the DHBC can be used for other functions as well. Since the amount of memory available to a DHBC cluster is very large (some implementations have terabytes) depending on the capacity and number of machines in the cluster, the cache can be used to keep almost anything in memory.
One possible example might be to cache the complete list of candidates or jobs for an important client to get extreme performance and take load away from the database. Other possibilities include anything that can take the load off the database such as caching frequently searched result sets and expiring them after a certain amount of time. It also should be possible to cache frequently accessed assets (pdf files, other documents, user uploaded images, etc.) and dynamically generated html pages (if they don’t change much).
Since the DHBC is shared across applications it should be possible to use it as a session sharing mechanism or general utility to keep information available for shared application usage without hitting the database.
Once the cache is complete, available, and tested, more thought should be done to find new imaginative ways in which the cache can be leveraged to improve performance and scalability in our applications.
MemCachedVsEhCache
Overview
Two distributed cache servers; Ehcache (Distributed Caching With Terracotta) and Memcached were evaluated to determine which one better fits the needs of our product. They were evaluated in various areas including ease of configuration, API usage, and overall speed.
Hardware
Client Machine:
AMD Sempron 2800+
1.61. GHz, 2 GB RAM
Windows Server 2003, Service Pack 2
Server Machine:
Dell Optiplex 740
Intel Core 2 CPU 6700
2.66 GHz, 1 GB RAM
Windows Server 2003, Service Pack 2
Software
Memcached Software:
Server:memcached-x86 1.4.5 binary for Windows
Test Client:spymemcached 2.5
Ehcache Software:
Server:terracotta-3.4.0 (Single Server Array)
Test Client:Ehcache 2.3.1
Configuration
Both cache servers were relatively easy to setup. For Memcached, a windows 1.4.5 version binary (memcached.exe) was used (I can’t recall the source url). Running memcached –h gives a list of the available options. For this evaluation memcached –m was the only option used to specify the maximum amount of memory to allow. For Ehcache, Ehcache 2.3.1 (ehcache-core-2.3.1-distribution.tar.gz) along with Terracotta 3.4.0 (terracotta-3.4.0_1-installer.jar) was downloaded from http://ehcache.org. The Terracotta installer, invoked with java -jar terracotta-3.4.0_1-installer.jar was easy to follow. The server can be started using the bin\start-tc-server.bat script in the installation folder. In summary, both cache servers are relatively easy to configure. I would probably give the edge here to Ehcache simply because there is a wealth of options available and they are well documented. Additionally, Ehcache uses a configuration file (ehcache.xml), which allows for different cache configurations which are selected at runtime.
API Usage
Both API’s are relatively simple to use. Adding, retrieving and deleting elements is straightforward.
Ehcache
import net.sf.ehcache.Cache;
import net.sf.ehcache.CacheManager; import net.sf.ehcache.Element;
public class Ehcache implements ICache
{
CacheManager mCacheManager;
Cache mCache;
public void init() throws Exception
{
InputStream fis = new FileInputStream(new File(<config file>))
try
{
mCacheManager = new CacheManager(fis);
mCache = mCacheManager.getCache(<cache name>);
}
finally
{
fis.close();
}
}
public void put(String pKey,Object pValue) throws Exception
{
mCache.put(new Element(pKey,pValue)); }
public Object get(String pKey) throws Exception
{
Element lElement = mCache.get(pKey);
if (lElement != null)
return lElement.getObjectValue();
return null;
}
public void remove(String pKey) throws Exception
{
mCache.remove(pKey);
}
}
MemCached
import java.net.InetSocketAddress;
import java.util.Arrays;
import net.spy.memcached.MemcachedClient;
import com.kenexa.core.data.dhbc.system.memcached._DefaultConnectionFactory;
public class Memcached implements ICache
{
MemcachedClient mMemcachedClient;
public void init() throws Exception
{
String lHost = "192.168.10.101";
int lPort = 11211;
InetSocketAddress address = new InetSocketAddress(lHost,lPort);
mMemcachedClient = new MemcachedClient(new _DefaultConnectionFactory(), Arrays.asList(address));
}
public void put(String pKey,Object pValue) throws Exception
{
mMemcachedClient.set(pKey,3600,pValue);
}
public Object get(String pKey) throws Exception
{
return mMemcachedClient.get(pKey);
}
public void remove(String pKey) throws Exception
{
mMemcachedClient.delete(pKey);
}
}
Ehcache additionally provides the ability to iterate the keys in the cache and extract statistical and other information which can be used to implement custom analysis tools. For this reason, I would rate Ehcache’s API better.
Performance
In order to evaluate the performance of both cache servers, the add, retrieve and remove operations were compared.
Test 1: Add
In the first test, fixed sized random byte arrays were added to the cache and the time to complete each set in milliseconds was recorded. I started with Ehcache and added 1000 random byte arrays of 1K, 10K and 100K followed by 10000 arrays of 1K and 10K. Finally, 2500 100K and 500 500K arrays were added. Each test was ran three (3) times to ensure the results were valid and the server software was stopped and restarted for each test to allow for consistent results. I then repeated the same tests for Memcached. The median result for each test is posted below.
Result:
Memcached’s outperformed Ehcache in these tests. I had initially collected some baseline numbers by running the same tests using only the client machine to host both the test client and cache server and the results were consistent with using two servers.
Add 1000 1K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 4750
Memcached 781
Add 1000 10K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 5500
Memcached 2078
Add 1000 100K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 18547
Memcached 4735
Add 10000 1K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 28094
Memcached 9360
Add 10000 10K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 38718
Memcached 11094
Add 2500 100K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 44937
Memcached 12531
Add 500 500K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 35953
Memcached 14500
Test 2: Add – Remove
In this test, fixed sized random byte arrays were added and removed from the cache and the time to complete each set in milliseconds was recorded. I started with Ehcache and added/removed 1000 random byte arrays of 1K, 10K and 100K followed by 10000 arrays of 1K and 10K. Finally, 2500 100K and 500 500K arrays were added/removed. Each test was ran three (3) times to ensure the results were valid and the server software was stopped and restarted for each test to allow for consistent results. I then repeated the same tests for Memcached. The median result for each test is posted below.
Result:
Memcached’s performance was again faster in this scenario.
Add-Remove 1000 1K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 6047
Memcached 1204
Add-Remove 1000 10K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 6578
Memcached 2891
Add-Remove 1000 100K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 17109
Memcached 5516
Add-Remove 10000 1K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 33172
Memcached 15641
Add-Remove 10000 10K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 37828
Memcached 20875
Add-Remove 500 500K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 34500
Memcached 14468
Add-Remove 2500 100K Byte Arrays
Cache Server Time (milliseconds)
Ehcache 44766
Memcached 14141
Test 3: MultiThreaded Get for 15 minutes
In this test, 1000 100K random byte arrays were first loaded to each cache server. Ten (10) threads were then created in the test client and each thread repeatedly retrieved random elements from the cache. A checksum was included with the added data and used during retrieval to ensure that the data was valid. Each test ran for 15 minutes to see how many records could be retrieved in that time period. There was no delay between operations. The average retrieval time per thread is also included.
Result:
Ehcache
runGetTestThreaded(Ehcache,1000 elements,size[102400] - 10 threads : 900 secs)
Thread Thread[Thread-19,5,] count = 8096, Avg Get Time = 110.49085968379447
Thread Thread[Thread-20,5,] count = 8072, Avg Get Time = 110.78889990089198
Thread Thread[Thread-21,5,] count = 8188, Avg Get Time = 109.18075232046898
Thread Thread[Thread-22,5,] count = 8143, Avg Get Time = 109.89942281714356
Thread Thread[Thread-23,5,] count = 8097, Avg Get Time = 110.44646165246388
Thread Thread[Thread-24,5,] count = 8054, Avg Get Time = 111.07946362056121
Thread Thread[Thread-25,5,] count = 8144, Avg Get Time = 109.85940569744598
Thread Thread[Thread-26,5,] count = 8094, Avg Get Time = 110.57289350135903
Thread Thread[Thread-27,5,] count = 8040, Avg Get Time = 111.2957711442786
Thread Thread[Thread-28,5,] count = 8129, Avg Get Time = 110.07467093123385
Total Count = 81057
Memcached
runGetTestThreaded(Memcached,1000 elements,size[102400] - 10 threads : 900 secs
Thread Thread[Thread-1,5,] count = 9580, Avg Get Time = 93.30365344467641
Thread Thread[Thread-2,5,] count = 9579, Avg Get Time = 93.33312454327174
Thread Thread[Thread-3,5,] count = 9579, Avg Get Time = 93.35369036433866
Thread Thread[Thread-4,5,] count = 9579, Avg Get Time = 93.3253993109928
Thread Thread[Thread-5,5,] count = 9579, Avg Get Time = 93.35953648606326
Thread Thread[Thread-6,5,] count = 9581, Avg Get Time = 93.27439724454649
Thread Thread[Thread-7,5,] count = 9581, Avg Get Time = 93.29683749086735
Thread Thread[Thread-8,5,] count = 9581, Avg Get Time = 93.25988936436697
Thread Thread[Thread-9,5,] count = 9580, Avg Get Time = 93.27651356993736
Thread Thread[Thread-10,5,] count = 9580, Avg Get Time = 93.25490605427974
Total Count = 95799
Memcached performance was slightly faster in this test. As it terms out, Ehcache has an option maxElementsInMemory, which sets the maximum number of objects that will be created in memory. Setting this value to 1000 and restarting the test yields the following results.
runGetTestThreaded(Ehcache,1000 elements,size[102400] - 10 threads : 900 secs)
Thread Thread[Thread-19,5,] count = 188456, Avg Get Time = 0.06041728573247867
Thread Thread[Thread-20,5,] count = 187452, Avg Get Time = 0.06884429080511277
Thread Thread[Thread-21,5,] count = 188048, Avg Get Time = 0.046940142942227515
Thread Thread[Thread-22,5,] count = 189150, Avg Get Time = 0.0383187946074544
Thread Thread[Thread-23,5,] count = 186504, Avg Get Time = 0.05214365375541544
Thread Thread[Thread-24,5,] count = 191792, Avg Get Time = 0.06031534162008843
Thread Thread[Thread-25,5,] count = 187647, Avg Get Time = 0.046033243270609175
Thread Thread[Thread-26,5,] count = 190728, Avg Get Time = 0.04553605134012835
Thread Thread[Thread-27,5,] count = 187245, Avg Get Time = 0.03894897060001602
Thread Thread[Thread-28,5,] count = 187020, Avg Get Time = 0.04590418137097636
Total Count = 1884042
Almost 2 million results and there was no cpu activity on the server. What this means is that Ehcache when used with Terracotta as a distributed cache, has the ability to also provide a local store. This is something that I’ve been meaning to incorporate into the current framework but I hadn’t figured out the best way to keep the local cache in sync with the server. There are instances where we will not always want to go over the network to retrieve cache data so this is a feature we will want to leverage.
Conclusion
There are other factors not included in the above results. At times restarting the Memcached server (which I did a lot) proved problematic as the client would experience errors where I was not sure of the actual cause. I was able to solve these issues by stopping the server and waiting for about a minute or two. Sometimes I had to restart the machine. Some of my tests not mentioned above proved too much for Ehcache as the garbage collector could not keep up and the process would run out of memory whereas Memcached had no problems. Overall, Memcached performed better and was less resource and cpi intensive. Even so, I believe that Ehcache is the better option for our product. The ability to have a local store for the most recently used objects per cache (our cache) would allow for less initial code changes. For example, code that accesses the same object repeatedly in a loop could stay that way without heavily impacting the application. We would want to rewrite such logic eventually but we wouldn’t be forced to do so up front. Also, in terms of monitoring, there seems to be better tools available for Ehcache. I’ve only glanced over them but another advantage is that the API for Ehcache allows exploration into the cache itself (i.e. a listing of all available keys), whereas I don’t believe the Memcached API has any such functionality.
Refactoring Techniques
What is Refactoring anyways?
Refactoring is the process of changing a computer program's source code without modifying its external functional behavior in order to improve some of the non-functional attributes of the software. It is a disciplined technique for restructuring an existing body of code, altering its internal structure without changing its external behaviour. Advantages include improved code readability and reduced complexity to improve the maintainability of the source code, as well as a more expressive internal architecture or object model to improve extensibility.
Its heart is a series of small behavior preserving transformations. Each transformation (called a 'refactoring') does little, but a sequence of transformations can produce a significant restructuring. Since each refactoring is small, it's less likely to go wrong. The system is also kept fully working after each small refactoring, reducing the chances that a system can get seriously broken during the restructuring. By continuously improving the design of code, we make it easier and easier to work with. If you get into the hygienic habit of refactoring continuously, you'll find that it is easier to extend and maintain code.
Motivation for Refactoring
Refactoring is usually motivated by noticing a code smell. For example the method at hand may be very long, or it may be a near duplicate of another nearby method. Once recognized, such problems can be addressed by refactoring the source code, or transforming it into a new form that behaves the same as before but that no longer "smells". For a long routine, extract one or more smaller subroutines. Or for duplicate routines, remove the duplication and utilize one shared function in their place. Failure to perform refactoring can result in accumulating technical debt. There are two general categories of benefits to the activity of refactoring.
- Maintainability. It is easier to fix bugs because the source code is easy to read and the intent of its author is easy to grasp. This might be achieved by reducing large monolithic routines into a set of individually concise, well-named, single-purpose methods. It might be achieved by moving a method to a more appropriate class, or by removing misleading comments.
- Extensibility. It is easier to extend the capabilities of the application if it uses recognizable design patterns, and it provides some flexibility where none before may have existed.
Before refactoring a section of code, a solid set of automatic unit tests is needed. The tests should demonstrate in a few seconds that the behaviour of the module is correct. The process is then an iterative cycle of making a small program transformation, testing it to ensure correctness, and making another small transformation. If at any point a test fails, you undo your last small change and try again in a different way. Through many small steps the program moves from where it was to where you want it to be. Proponents of extreme programming and other agile methodologies describe this activity as an integral part of the software development cycle.
List of refactoring techniques
Here is a very incomplete list of code refactorings. A longer list can be found in Fowler's Refactoring book and on Fowler's Refactoring Website.
Techniques that allow for more abstraction
- Encapsulate Field – force code to access the field with getter and setter methods
- Generalize Type – create more general types to allow for more code sharing
- Replace type-checking code with State/Strategy
- Replace conditional with polymorphism
- Extract Method, to turn part of a larger method into a new method. By breaking down code in smaller pieces, it is more easily understandable. This is also applicable to functions.
- Extract Class moves part of the code from an existing class into a new class.
- Move Method or Move Field – move to a more appropriate Class or source file
- Rename Method or Rename Field – changing the name into a new one that better reveals its purpose
- Pull Up – in OOP, move to a superclass
- Push Down – in OOP, move to a subclass
Writing Effective Designs
Overview
As the software development is maturing, the HLDs and LLDs are widely accepted as an integrated part of software development cycle, no matter what software development methodology we use. Even though the need of having a design is accepted and 30% to 40% of the total development effort is spent on design, it is rare to see effective designs that lay strong foundation for the application development. Very often they fail miserably in providing guidance and clarity for the development teams to start with and as a result the actual implementations are miles apart from the original design. In fact, in many cases the only useful purpose design serves is to complete the list of deliverables for the project for its closure and audits.
Writing effective design is one way to prevent such situations. This tutorial attempts to suggest a step by step approach to develop and deliver effective designs that shall not only be followed and respected by developer community but also play key role in development of stable and robust application.
What is design?
Before we get into the details about writing effective design, it is important that we have the same understanding about what the design is that we are referring to here. Here we are essentially talking about HLDs and LLDs for software development which is an essential part of software development and should ideally be available before the start of development face of the project.
What is an HLD?
- Is a document or/and set of UML artifacts that defines the higher level component view of the system
- Usually includes a high-level architecture diagram depicting the components, interfaces and networks that need to be further specified or developed.
- Mentions every work area briefly, clearly delegating the ownership of more detailed design activity to the concerned LLDs.
- May define high level domain model and interaction diagram which shall be elaborated in LLDs
- Defines boundaries of the system, possible subsystems and establish communication methodologies within various sub-systems
- HLD contains details at macro level and so it cannot be given to programmers as a document for coding
- Documents HLD decisions stating the reason for the design decision. For example using Struts2 framework over Spring MVC.
- Is used by designers or senior developers to create LLDs for their subsystems strictly following the boundaries, interfaces and guidelines provided in HLD
- Is used as program specification by the developers to develop the code for the subsystem that the LLD is written for
- Is at the lowest level of abstraction before the code itself and clearly define the methods, their parameters return types and interaction with dependencies
- Contains low level domain model and details each and every property of all domain objects
- May contain separate low level ER diagram representing the tables participating in the LLD
- In most cases uses HLD as the input criteria
- Documents LLDs decisions stating the reason for the design decision. For example using inner class rather than separate class.
Why we need HLD?
- It serves as a communication tool that speaks to and for all stakeholders of the project. HLD is responsible for establishing vocabulary for the project that helps in project related communication across designers and developers
- It defines overall architecture and subsystems of the application and fulfills all functional and well non-functional requirements which is most important aspect from customer’s point of view
- It enforces standards by publishing guidelines for services and components development
- It bridges the gap between functional and technical views of the system and brings the two view points together to discuss and close issues that are important for the success of the project.
- Creates lower level abstractions of the requirements for the low level designers to work on by breaking up the requirements into deliverable UCs and features. However, the abstraction level is not low enough to hand it over to developer for coding based on it and that’s why we need LLD.
- Starting point or input criteria for LLD
- Helps in thinking ahead and being proactive for low level development related issue. It is a know fact that the early we find an issue the lesser it costs. LLD provides an opportunity for thinking ahead and being proactive about the problems that might come up at later stages of the development. Such issues can be addressed and fixed early in the design phase resulting in stable code and costing less.
- Finalizing implementation strategy for a project before actually implementing it and hence reducing conflicts in development phase and resulting in faster development
- Providing program specifications to the developers and sparing them for doing what they are best at (coding) rather than confusing them with very high level requirements from requirement documents
- LLD provides further lower level abstractions of the requirements and can be handed over to developers for coding programs based on that. So LLD is the input for the development phase of the project
It is important for the management to be able to quantify effectiveness of a design. Following are a few signs that a good manager should always be looking at to find out if the designs are effective or not.
Characteristics of an ineffective HLD
Following are some signs for ineffective HLD
- LLDs are inefficient (More about it in later section about LLD)
- There are too much discussions happening among high level designer and low level designers instead of resolving issues via query register. This is a clear hint that something is wrong somewhere.
- HLD’s inefficiencies are felt by the LLD designers and still it is not able to convince them or adapt itself to address these inefficiencies
- HLD does not clearly specifies the high level domain model and high level interaction diagrams for all the subsystems defined
- All subsystems and system boundaries are not specified clearly
- Non functional requirements are not addressed and fulfilled
- In LLDs there are significant deviations from the guidelines and service interaction models established in HLD
- Non technical people cannot understand it
Following are some signs for ineffective LLD
- Its inefficiencies are felt and told by the developers and still it is not able to convince them or adapt itself to address these inefficiencies before it is too late
- There are significant deviations from the design in the actual implementation
- Developers have to refer to HLD, SRS, UCs and other documents etc to get more clarity on implementation process
- The code is unstable and defect churn rate is high
- The LLD is not being referred for the actual implementation
- Huge refactoring activities are occurring in the code to stabilize it
- It has not been reviewed by the author of HLD on which the LLD is based on
- Development is taking much more then planned effort
Problems with HLD
- Lack of technical and business understanding for HLD: One common cause for inefficient design is the fact that the designers/architects/developers are not competent enough to do that. A good mix of business and technical knowledge is required to come up with good HLD. Even a slightly biased view towards business or technology can disrupt the balance and effectiveness of the HLD
- Technology dominates business: It is important for a designer to keep a view of all functional and non-functional requirements that need to be addressed and not to get carried away by the promises and robustness of new frameworks and patterns. No matter how smart technology, architectures, frameworks and patterns you have used, it is all waste unless it meets customer requirements and satisfaction. Loosing focus on these results in ineffective designs.
- Jazzy UML: The design may or may not have strict UML compliant diagrams as long as it can clearly indicate the intentions of the designer and the design decisions that he has taken. On the contrary the designer at times are more concerned about the UML compliance then the real need of design which leads to jazzy and nicely looking but ineffective designs.
- Lack of willingness to do LLD before coding: Now that programming languages are evolving to be at higher level of abstraction and delivery mindset is to deliver fast and quick. Design has taken a back seat. Developers feel that every hour they are not writing code shall result in extra hours of overtime later at the time of delivery. This mindset has taken its toll on the quality of design.
- Experimenting with new concepts and patterns: LLD designers often want to introduce modern design patterns and concepts into there design just for the sake of it. This ends up in unnecessary complexity in LLD for developer to understand. Most of the times a lot of irrelevant information is added in the design which is seldom looked at by the readers
- Less documented information and more Diagrams: Diagrams are great tool for visualizing design but they cannot convey the thought process that the designer has gone through to come up with that design. Diagram might reflect the design decisions that the designer of the LLD has taken but can not explain the motivation behind those decisions. It is important for developers to understand the reason and thinking that has gone into it to avoid conflicts and gain consent.
- One template doesn’t fit all projects: Each software development project is different from the other in some aspects which imply that same information and document structure may not meet all the needs for all the projects. Some thought must go into customizing design template to meet specific needs of a project.
It is equally important to for the delivery management to know if the design is effective as it is to know if it is not. It is management’s responsibility to not only improve the inefficiencies but also to encourage and carry forward and continue with the best practices and good design methodologies that are being followed.
Characteristics of an effective HLD
- It is at just right level of abstraction so that it makes sense for all stake holders of the project including developers, designers and business analysts. It should speak for and to all stake holders of the project
- It should clearly state all the functional and nonfunctional requirements of the project along with providing high level solutions for achieving them
- Clearly identify all subsystems of the project and defines clear cut framework for enabling communication within these subsystems
- Describes all the layers of the system and integration points with external and internal services
- It should be able justify all aspects of design decisions taken in the HLD. If any aspect of the design cannot be justified, then it is probably worth reevaluating
- It should document all benefits that results from the design decision
- LLDs built on the effective HLD are effective as well and so is the code built on those LLDs. However, waiting this long to check the effectiveness of an HLD is not a good idea and it may be too late for any corrective actions.
- It clearly documents all assumptions, dependencies and risks for the project and allow project manager a chance to arrange the dependencies, confirm the assumptions and mitigate the risks
- An effective design is a live document that continues to navigate and control the implementation and development process for complete life cycle of the project. It is not dumped aside after first few references.
- It meets the system requirements in a meaningful way and explains the thought process that has gone into for arriving to the design decisions taken in the design
- Code developed on effective LLD is stable and maintainable and churn rate of defects is not much.
- It is at the lowest level of abstraction and provides sufficient clarity for the developer to start coding right away without having to wait for detailed one to one sessions for starting coding for a LLD
So far we have discussed the characteristics of an effective as well as an ineffective design and also the importance of the design and why do we need it. Now it is time that we should get our hands dirty with the real stuff “Writing effective design”. Here we shall discuss the prerequisites and the step by step approach to create effective HLDs and LLDs for a project.
Prerequisites for an effective HLD
- Baseline Requirements: It is always difficult to aim and hit at a moving target. To come up with an effective HLD you need to have complete control over the scope of your design. You need to have base lined requirements before you start with the design. Obviously, the requirements are going to change sometimes but it is better to have clear agreement on base-lined requirements so that you have the scope of negotiation if the requirements change drastically during or after the design.
- Architecture document: There is a wide misconception that architecture is a part of HLD. However, it should not be that way and in fact there should be a separate architecture document for the project describing at least business architecture, information architecture, data architecture and application architecture of the system. The HLD may include references to that document or some specific part of it to throw more light on some HLD decisions. HLD is meant to talk to and for all stake holders of the project and having all these architecture documented inside HLD makes it meaningless for a section of audience. Also, architecture will overshadow the HLD, reducing and diluting the impact that it should have.
- Design template: Same HLD template may not be able to cater all types of projects as every project has a uniqueness that may require customized solutions. It is responsibility of the high level designer to think through and come up with a HLD and LLD template suitable for the project. These templates should typical have the buy-in from business analysts, low level designers, developers and other stake holders of the project
- Thorough understanding of all these documents: This is the most important point and design must not start without the designer having clear understanding of the documents described above.
- Query Register: All queries and confusions that the designer has about anything mentioned in these documents should be resolved before the start of design and the same should be documented neatly in project specific query register so that analysts, designers and developers can access it if required to clarify or respond to queries. The query register should act as a knowledge base for the project.
- Scope of design is often considered as mere formality and is filled up as last part of the design and is mostly copied from the similar designs that are already available. Some minor tweaks here and there in the copied scope and is considered done. However, this is where we are risking the entire foundation of the project.
- For HLDs scope section should clearly list down the project specific feature scope and it should be in agreement with the business analysts. Break down the requirements in to deliverable UCs and if required split the complex uses cases into independently manageable features for better traceability.
- High level designer should not only be clear about the scope for HLD but should also have a clear view about the breakups and scope for the LLDs that need to be developed based on the HLD. He should have the clear release plan for the LLDs and corresponding implementations.
- High level domain model should define the most important domain objects and the relationships among them. This is an important step as in most cases and with the modern persistence frameworks being used, this part is going to define your database which will eventually become the backbone of your application. Effective domain modeling is must for an effective HLD.
- First step for the designer is to identify the domain objects or entities for you project. For this a common way is to do it by reading the requirements and list down all the nouns that appear in the requirement. This is followed by elimination of duplicates and visibly irrelevant ones from the list. After this step is performed you should be ready with the first draft of domain objects. At this point it is important to get these objects verified from the domain expert. In fact ideally domain expert should be part of the domain object identification session.
- Once domain objects are identified, you would need to think about the relationships between them. At this point it is probably ok to draw your first class diagram which is the high level domain model. The domain model can be at a higher level specifying associations and dependency relationships between domain objects. It should be attached with some relevant notes for low level designers about how and what to elaborate in it in their LLDs
- Components or sub-system identification is the next important activity that the designer has to perform for effective HLD. This is a brain storming exercise that must be done by the high level designers. After this activity is done the designer should have clear view of various subsystems and reusable components of the application and probably also have some idea about how the communication shall work within these components.
- Once all internal and external subsystems and components are identified, the designer has to think through the integration issues and challenges for enabling smooth and effective communication among these systems and at this point should draw the component diagram for the application. How a component shall be reused should be decided at this point.
- High level service model is the next step which should be performed and this step varies depending upon various factors related to development methodologies, technologies, frameworks, project domain and other project specific parameters.
- After this step is complete you should have identified higher level components of your service layer. Service layer image should be drawn in your mind that you would need to resolve specific queries from the low level designers.
- Identify subsystems and integration points may be the next in the HLD. This activity normally goes on throughout the development of your HLD. However it is important to list the entire internal and external component that you can think of. The list can be refined and polished as the HLD progresses.
- At this point you should plot the component diagram for your project clearly specifying all subsystems internal and external and the interaction between them.
- Provide realization of identified UCs in the scope section. After all the above steps are done you would need to provide the high level realization for your UCs. For measuring the real progress and completion status of the development it may be required to introduce the concept of features.
- One feature may be involved in the realization of several UCs
- Full realization of a UC requires the implementation of all supporting features.
- At this point high level designer would need to provide some interaction diagrams like sequence diagram or collaboration diagrams for each feature and UC. These diagrams may be at a very higher level indicating the message flow among various objects across various layers of the application and providing clear integration points that should be further elaborated on in LLDs.
- High level designer may have to discuss the integration points and strategies with the architecture team to ensure that it fits in the overall integration architecture of the system. Also designer has to ensure that architecture guidelines are followed and the HLD doesn’t violate any aspect of architecture. That is why it was mentioned that the high level designer should thoroughly understand the application architecture.
Apart from all the prerequisites for HLD, the LLD designer should ensure that following artifacts are available before he/she starts with the LLD
- HLD is the most important artifact that the low level designer should have with him before he starts with the LLDs. HLD establishes a contract and vocabulary that needs to be respected by the LLD and implementation code.
- High level scope for the LLD. This should typically be provided by the high level designer who has the complete visibility about entire project and all LLD developments that may be going on in parallel. High level designer may have decided to break the functionality defined in the HLD in multiple LLDs and may have some planning about each LLD release. LLD designer must have the clear understanding about the things that are in scope of his LLD and also the overall release plan so that he can align his priorities with the project priorities.
- Query register should be in place while the HLD was being created and should have query resolutions from the HLD phase. LLD designer should have access to this knowledge base so that he has clarity on business related discussions that might have happened in HLD phase and that are logged in there.
- Designer should first have complete clarity on scope of his LLD. He should analyze the scope provided by the high level designer and if required break it up further into some lower level scope items.
- Low level domain model is the next thing that the designer has to create.
- For this the designer should identify all properties and behaviors for each domain object and it should be filled in each entity in the low level class diagram.
- Designer should also identify other domain objects that may not have been identified in HLD but may be required in LLD for its implementation.
- Low level designer should name domain object as per project specific naming convention and should also name all the relationships between domain object along with the multiplicity of the relationships. This step is required for the developer to come up with a stable entity relationship model quickly.
- Low level domain model should be at as lower level as possible to the code and should have one to one mapping with entities that are created in the code. Don’t expect and allow the developer to think and apply there thoughts in this area as domain model is the back bone of your application which you cannot afford to expose to the developer to mess around with.
- Realization of the UCs and the features is the next step for the LLD designer. Designer has to work closely with the developers and should be aware of the lower level APIs of the code. It is important for the designer to have this knowledge to come up with design that is closer to the reality.
- First step here is to study the higher level interaction diagram that HLD designer has provided to understand the integration points with internal and external components and interaction between various layer of the system
- Next step if to do some lower level detailing for each interaction defined. For example the HLD may only mention that your service needs to talk to some external LDAP service for authentication. The low lever designer should however provide the complete flow that realizes that interaction. This would include exact class names, method name, parameters and return type.
- So the high level sequence diagram may have only important participating component but the lower level sequence diagrams should have all the participating objects for that flow at lowest level of abstraction.
- Each method call should be clearly defined in the interaction diagram giving no way to any confusion for the developer. At this point the designer has to see his diagrams from developer’s perspective and scrutinize it for lack of information. All findings should be corrected.
- Document all the design decisions in the notes within the sequence diagrams. It is better to document all the design decisions, assumptions and dependencies related to an interaction diagram in a note within that diagram itself rather then putting all these in one section of the LLD. This helps the developer in relating to the thought process of the LLD designer while designing that flow.
- If required it is also a good practice to provide pseudo code for complex part of an interaction diagram. More information you provide for your flows, lesser thinking developers have to do. It is a known fact the earlier you think of a problem better control you have on them. So it is worth thinking and writing pseudo code for complex part of the interaction in the LLD itself.
- Please don’t experiment with new design patterns or fancy stuff just for the sake of it and stick to what is known to work with your project. It doesn’t mean that you should kill your ideas and creativity. All I am trying to convey here is that to be pragmatic and ensure that you have done POCs before you are introducing something new in your design. Putting things in design first and then doing the POCs for them is not a good idea and is a huge risk for your project.
- The important skill that designer need to develop is to have a flexible and open mindset. He should be able to think from perspective of an analyst and a developer, both at the same time and need to maintain a fine balance between them for the benefit of project.
- Without complete clarity about the domain it is nearly impossible to come up with effective design for applications that are meant to work on that domain.
- It certainly helps the designer if he has good command over UML as it helps creating accurate interaction diagrams quickly. However, it is still possible to come up with good design even if the designer in not an expert at UML but has an analytical mindset and can clarify his intentions and design decisions in the design document.
- High level domain model, components of the system, clear and justified design decisions, assumptions, dependencies and risks for the project are some important things that must be included in the HLD.
- Low level designs should be at lowest level of abstraction and should not allow the developer to think and take decisions that are critical for the application. All these decisions should be taken while developing the LLD.
- All POCs should be done prior to suggesting new design patterns, technologies and approaches that the developers are not familiar with. Suggesting first and doing later may be a risk for the project and is a big NO.
Web Site Scalability
A classical large scale web site typically have multiple data centers in geographically distributed locations. Each data center will typically have the following tiers in its architecture
- Web tier : Serving static contents (static pages, photos, videos)
- App tier : Serving dynamic contents and execute the application logic (dynamic pages, order processing, transaction processing)
- Data tier: Storing persistent states (Databases, Filesystems)
Content Delivery
Dynamic Content
- Most of the content display is dynamic content. Some application logic will be executed at the web server which generate an HTML for the client browser. The efficiency of application logic will have a huge impact on the overall site's scalability. This is our main topic here.
- Sometimes it is possible to pre-generate dynamic content and store it as static content. When the real request comes in, instead of re-running the application logic to generate the page, we just need to lookup the pre-generated page, which can be much faster
- Static content are typically the images, videos embedded inside the dynamic pages.
- A typical HTML pages typically contains many static contents where the browser will make additional HTTP network round trips to fetch. So fetching static content efficiency also has a big impact to the overall response of dynamic page
- Content Delivery Network is an effective solution for delivering static contents. CDN provider will cache the static content in their network and will return the cached copy for subsequent HTTP fetch request. This reduce the overall hits to your web site as well as improving the user's response time (because their cache is in closer proximity to the user)
There are 2 layers of dispatching for a Client who is making an HTTP request to reach the application server
DNS Resolution based on user proximity
- Depends on the location of the client (derived from the IP address), the DNS server can return an ordered list of sites according to the proximity measurement. Therefore client request will be routed to the data center closest to him/her
- After that, the client browser will cache the server IP
- Load balancer (hardware-based or software-based) will be sitting in front of a pool of homogeneous servers which provide same application services. The load balancer's job is to decide which member of the pool should handle the request
- The decision can be based on various strategy, simple one include round robin or random, more sophisticated one involves tracking the workload of each member (e.g. by measuring their response time) and dispatch request to the least busy one
- Members of the pool can also monitor its own workload and mark itself down (by not responding to the ping request of the load balancer)
This is concerned about designing an effective mechanism to communicate with the client, which is typically the browser making some HTTP call (maybe AJAX as well)
Designing the granularity of service call
- Reduce the number of round trips by using a coarse grain API model so your client is making one call rather than many small calls
- Don't send back more data than your client need
- Consider using an incremental processing model. Just send back sufficient result for the first page. Use a cursor model to compute more result for subsequent pages in case the client needs it. But it is good to calculate an estimation of the total matched result to return to the client.
- If you have control on the client side (e.g. I provide the JavaScript library which is making the request), then you can choose a more compact encoding scheme and not worry about compatibility.
- If not, you have to use a standard encoding mechanism such as XML. You also need to publish the XML schema of the message (the contract is the message format)
- If the message size is big, then we can apply compression technique (e.g. gzip) to the message before sending it.
- You are trading off CPU for bandwidth savings, better to measure whether this is a gain first
- AJAX fits very well here. User can proceed to do other things while the server is working on the request
- Consider not sending the result at all. Rather than sending the final order status to the client who is sending an order placement request, consider sending an email acknowledgment.
Typical web transaction involves multiple steps. Session state need to be maintained across multiple interactions
Memory-based session state with Load balancer affinity
- One way is to store the state in the App Server's local memory. But we need to make sure subsequent request land on the same App Server instance otherwise it cannot access the previous stored session state
- Load balancer affinity need to be turned on. Typically request with the same cookie will be routed to the same app server
- Another way to have the App server sharing a global session state by replicating its changes to each other
- Double check the latency of replication so we can make sure there is enough time for the replication to complete before subsequent request is made
- Store the session state into a DB which can be accessed by any App Server inside the pool
- Under this model, the cookie will be used to store the IP address of the last app server who process the client request
- When the next request comes in, the dispatcher is free to forward to any members of the pool. The app server which receive this request will examine the IP address of the last server and pull over the session state from there.
- If the session state is small, you don't need to store at the server side at all. You can just embed all information inside a cookie and send back to the client.
- You need to digitally sign the cookie so that modification cannot happen
Remember the previous result can reuse them for future request can drastically reduce the workload of the system. But don't cache request which modifies the backend state.
Source : http://horicky.blogspot.in/2008/03/web-site-scalability.html
Database Scalability
Database is typically the last piece of the puzzle of the scalability problem. There are some common techniques to scale the DB tire
Indexing
Make sure appropriate indexes is built for fast access. Analyze the frequently-used queries and examine the query plan when it is executed (e.g. use "explain" for MySQL). Check whether appropriate index exist and being used.
Data De-normalization
Table join is an expensive operation and should be reduced as much as possible. One technique is to de-normalize the data such that certain information is repeated in different tables.
DB Replication
For typical web application where the read/write ratio is high, it will be useful to maintain multiple read-only replicas so that read access workload can be spread across. For example, in a 1 master/N slaves case, all update goes to master DB which send a change log to the replicas. However, there will be a time lag for replication.
Table Partitioning
You can partition vertically or horizontally.
Vertical partitioning is about putting different DB tables into different machines or moving some columns (rarely access attributes) to a different table. Of course, for query performance reason, tables that are joined together inside a query need to reside in the same DB.
Horizontally partitioning is about moving different rows within a table into a separated DB. For example, we can partition the rows according to user id. Locality of reference is very important, we should put the rows (from different tables) of the same user together in the same machine if these information will be access together.
Transaction Processing
Avoid mixing OLAP (query intensive) and OLTP (update intensive) operations within the same DB. In the OLTP system, avoid using long running database transaction and choose the isolation level appropriately. A typical technique is to use optimistic business transaction. Under this scheme, a long running business transaction is executed outside a database transaction. Data containing a version stamp is read outside the database trsnaction. When the user commits the business transaction, a database transaction is started at that time, the lastest version stamp of the corresponding records is re-read from the DB to make sure it is the same as the previous read (which means the data is not modified since the last read). Is so, the changes is pushed to the DB and transaction is commited (with the version stamp advanced). In case the version stamp is mismatched, the DB transaction as well as the business transaction is aborted.
Object / Relational Mapping
Although O/R mapping layer is useful to simplify persistent logic, it is usually not friendly to scalability. Consider the performance overhead carefully when deciding to use O/R mapping.
There are many tuning parameters in O/R mapping. Consider these ...
- When an object is dereferenced, how deep the object will be retrieved
- If a collection is dereferenced, does the O/R mapper retrieve all the object contained in the collection ?
- When an object is expanded, choose carefully between multiple "single-join" queries and single "multiple join" query
Scalable System Design
Building scalable system is becoming a hotter and hotter topic. Mainly because more and more people are using computer these days, both the transaction volume and their performance expectation has grown tremendously.
This one covers general considerations. I have another blogs with more specific coverage on DB scalability as well as Web site scalability.
General Principles
"Scalability" is not equivalent to "Raw Performance"
- Scalability is about reducing the adverse impact due to growth on performance, cost, maintainability and many other aspects
- e.g. Running every components in one box will have higher performance when the load is small. But it is not scalable because performance drops drastically when the load is increased beyond the machine's capacity
- Dimension of growth and growth rate: e.g. Number of users, Transaction volume, Data volume
- Measurement and their target: e.g. Response time, Throughput
- Rank the importance of traffic so you know what to sacrifice in case you cannot handle all of them
- Scale the system horizontally (adding more cheap machine), but not vertically (upgrade to a more powerful machine)
- The ability to swap out old code and replace with new code without worries of breaking other parts of the system allows you to experiment different ways of optimization quickly
- Never sacrifice code modularity for any (including performance-related) reasons
- Bottlenecks are slow code which are frequently executed. Don't optimize slow code if they are rarely executed
- Write performance unit test so you can collect fine grain performance data at the component level
- Setup a performance lab so you can conduct end-to-end performance improvement measurement easily
- Do regular capacity planning. Collect usage statistics, predict the growth rate
Common Techniques
Server Farm (real time access)
- If there is a large number of independent (potentially concurrent) request, then you can use a server farm which is basically a set of identically configured machine, frontend by a load balancer.
- The application itself need to be stateless so the request can be dispatched purely based on load conditions and not other factors.
- Incoming requests will be dispatched by the load balancer to different machines and hence the workload is spread and shared across the servers in the farm.
- The architecture allows horizontal growth so when the workload increases, you can just add more server instances into the farm.
- This strategy is even more effective when combining with Cloud computing as adding more VM instances into the farm is just an API call.
- Spread your data into multiple DB so that data access workload can be distributed across multiple servers
- By nature, data is stateful. So there must be a deterministic mechanism to dispatch data request to the server that host the data
- Data partitioning mechanism also need to take into considerations the data access pattern. Data that need to be accessed together should be staying in the same server. A more sophisticated approach can migrate data continuously according to data access pattern shift.
- Most distributed key/value store do this
- The algorithm itself need to be parallelizable. This usually mean the steps of execution should be relatively independent of each other.
- Google's Map/Reduce is a good framework for this model. There is also an open source Java framework Hadoop as well.
- This is common for static media content. The idea is to create many copies of contents that are distributed geographically across servers.
- User request will be routed to the server replica with close proxmity
- This is a time vs space tradeoff. Some executions may use the same set of input parameters over and over again. Therefore, instead of redo the same execution for same input parameters, we can remember the previous execution's result.
- This is typically implemented as a lookup cache.
- Memcached and EHCache are some of the popular caching packages
- DBSession and TCP connection are expensive to create, so reuse them across multiple requests
- Instead of calculate an accurate answer, see if you can tradeoff some accuracy for speed.
- If real life, usually some degree of inaccuracy is tolerable
- Try to do more processing upstream (where data get generated) than downstream because it reduce the amount of data being propagated
- You make a call which returns a result. But you don't need to use the result until at a much later stage of your process. Therefore, you don't need to wait immediately after making the call., instead you can proceed to do other things until you reach the point where you need to use the result.
- In additional, the waiting thread is idle but consume system resources. For high transaction volume, the number of idle threads is (arrival_rate * processing_time) which can be a very big number if the arrival_rate is high. The system is running under a very ineffective mode
- The service call in this example is better handled using an asynchronous processing model. This is typically done in 2 ways: Callback and Polling
- In callback mode, the caller need to provide a response handler when making the call. The call itself will return immediately before the actually work is done at the server side. When the work is done later, response will be coming back as a separate thread which will execute the previous registered response handler. Some kind of co-ordination may be required between the calling thread and the callback thread.
- In polling mode, the call itself will return a "future" handle immediately. The caller can go off doing other things and later poll the "future" handle to see if the response if ready. In this model, there is no extra thread being created so no extra thread co-ordination is needed.
- Use efficient algorithms and data structure. Analyze the time (CPU) and space (memory) complexity for logic that are execute frequently (ie: hot spots). For example, carefully decide if hash table or binary tree should be use for lookup.
- Analyze your concurrent access scenarios when multiple threads accessing shared data. Carefully analyze the synchronization scenario and make sure the locking is fine-grain enough. Also watch for any possibility of deadlock situation and how you detect or prevent them. A wrong concurrent access model can have huge impact in your system's scalability. Also consider using Lock-Free data structure (e.g. Java's Concurrent Package have a couple of them)
- Analyze the memory usage patterns in your logic. Determine where new objects are created and where they are eligible for garbage collection. Be aware of the creation of a lot of short-lived temporary objects as they will put a high load on the Garbage Collector.
- However, never trade off code readability for performance. (e.g. Don't try to bundle too much logic into a single method). Let the VM handle this execution for you.
Scalable System Design Patterns
Load Balancer
In this model, there is a dispatcher that determines which worker instance will handle the request based on different policies. The application should best be "stateless" so any worker instance can handle the request.
Scatter and Gather
In this model, the dispatcher multicast the request to all workers of the pool. Each worker will compute a local result and send it back to the dispatcher, who will consolidate them into a single response and then send back to the client.
Result Cache
In this model, the dispatcher will first lookup if the request has been made before and try to find the previous result to return, in order to save the actual execution.
Shared Space
This model also known as "Blackboard"; all workers monitors information from the shared space and contributes partial knowledge back to the blackboard. The information is continuously enriched until a solution is reached.
Pipe and Filter
This model is also known as "Data Flow Programming"; all workers connected by pipes where data is flow across.
Map Reduce
The model is targeting batch jobs where disk I/O is the major bottleneck. It use a distributed file system so that disk I/O can be done in parallel.
Bulk Synchronous Parellel
This model is based on lock-step execution across all workers, coordinated by a master. Each worker repeat the following steps until the exit condition is reached, when there is no more active workers.
- Each worker read data from input queue
- Each worker perform local processing based on the read data
- Each worker push local result along its direct connection
This model is based on an intelligent scheduler / orchestrator to schedule ready-to-run tasks (based on a dependency graph) across a clusters of dumb workers.
Source: http://horicky.blogspot.com/2010/10/scalable-system-design-patterns.html
Misconceptions About Software Architecture
References to architecture are everywhere: in every article, in every ad. And we take this word for granted. We all seem to understand what it means. But there isn't any wellaccepted definition of software architecture. Are we all understanding the same thing? We gladly accept that software architecture is the design, the structure, or the infrastructure. Many ideas are floating around concerning why and how you design or acquire an architecture and who does it. Here are some of the most common misconceptions about Software Architecture.
Architecture and design are the same thing
Architecture is design, but is not all of the design. Architecture is about making decisions on how the system will be built, it stops at the major abstractions, the major elements - the elements that are structurally important, but also those that have a more lasting impact on the performance, reliability, cost, and adaptability of the system. In constrast, design involves a lot more in order to take the design to implementation. In a word, architecture is the fundamental, architecturally-significant aspects of the design.
Architecture and infrastructure are the same thing
The infrastructure is an integral and important part of the architecture: It is the foundation. Choices of platform, operating systems, middleware, database, and so on, are major architectural choices. Architecture must include the application architecture plus the infrastructure architecture. There is far more to architecture than just the infrastructure. The architects have to consider the whole system, including all applications otherwise an overly narrow view of what architecture is may lead to a very nice infrastructure, but the wrong infrastructure for the problem at hand.
Architecture is just a structure
Architecture is more than just the structural organization of design elements, it also includes the description of how these elements collaborate, as well as why things are the way they are (the rationale). The architecture must describer how the architecture fits into the current business context and must address how it can be developed within the current development context.
Architecture is flat and one blueprint is enough
Architecture is a complex beast; it is many things to many different stakeholders. Using a single blueprint to represent architecture results in an unintelligible semantic mess. Like building architects who have floor plans, elevations, electrical cabling diagrams, and so on, we need multiple blueprints to address different concerns, and to express the separate but interdependent structures that exist in an architecture.
Architecture cannot be measured or validated
Architecture is not just a whiteboard exercise that results in a few interconnected boxes and is then labeled a high-level design. The development of the architecture involves design, implementation, testing, etc. There are many aspects you can validate by inspection, systematic analysis, simulation, or modelization.
Architecture is Science
If there is a spectrum between art (creative) and science (prescriptive), architecture is somewhere in-between. The architecture problem space is quite large. One of the reasons that architecture cannot yet be considered a science is that there are no good guidelines on how to traverse the solution space, "prune it", and then apply the selected solutions. Architecture is becoming an engineering discipline (it is steadily moving toward the science end of the spectrum). Nevertheless, it is not a strict science because if you put two architect in seperate rooms, give them just the requirements, each will (most probably) come up with a different architecture. However, if you constrain them with a set of architectural patterns, their results will be more similar.
Architecture is an art
Let's not fool ourselves. The artistic, creative part of software architecture is usually very small. Most of what architects do is copy solutions that they know worked in other similar circumstances, and assemble them in different forms and combinations, with modest incremental improvements. It is possible to describe an architectural process that has precise steps and prescribed artifacts, and that takes advantage of heuristics and patterns that are starting to be better understood.
Two powerful principles to improve the design
Coupling is usually contrasted with cohesion. Low coupling often correlates with high cohesion, and vice versa.
Low coupling is often a sign of a well-structured computer system and a good design, and when combined with high cohesion, supports the general goals of high readability and maintainability.
The goal of this case study is to show the benefits of low coupling and high cohesion, and how it can be implemented with Java. The case study consists of designing an application that accesses a file in order to get data, processes it, and prints the result to an output file.
Solution without design:
For this first solution the design is ignored and only one class named DataProcessor is used to:
- Get data from file.
- Processing data.
- Print result.
And the main method invokes the methods of this class.
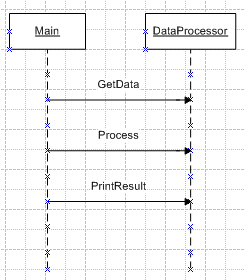
Drawback of this solution:
Low cohesion: DataProcessor class has many responsibilities so we can’t easily reuse algorithm in other application.
High coupling: the processing is high coupled with console and also with data provider.
Design refactoring:
- High Cohesion:
To improve cohesion each responsibility must be assigned to a different class so we need three classes:
FileProvider: To get data from File.
DataProcessing: To process data, and this class can use other classes to complete processing, but to simplify the design we consider that’s sufficient for our processing.
ResultReporting: To report result to file.
So each class has its own responsibility, here’s the advantages of this improvement:
- Easy to understand classes.
- Easy to maintain.
- Easy to reuse classes in other applications.
- Low coupling:
What happen if data exist in database not in file, in our last design our application is high coupled with file provider.
Using interfaces and abstract classes improve the low coupling, and the question is which type to use interface or abstract class?
Interface permit to define a conract without implementation, so no behavior logic exist for interfaces,however abstract classes let you define some default behaviors; and they force your subclasses to provide others.
Even you choose to use abstract class to define a default behavior, it’s better to provide also an interface, to disociate between the contract and the behaviour, this decoupling makes the code more flexible, and any changes in the behaviour will not impact a lot of your code if you use interfaces.
Let’s add an interface that provide methods to get data from anywhere , and for the case of file we need class that implement this interface.
Low cohesion: DataProcessor class has many responsibilities so we can’t easily reuse algorithm in other application.
High coupling: the processing is high coupled with console and also with data provider.
Design refactoring:
- High Cohesion:
To improve cohesion each responsibility must be assigned to a different class so we need three classes:
FileProvider: To get data from File.
DataProcessing: To process data, and this class can use other classes to complete processing, but to simplify the design we consider that’s sufficient for our processing.
ResultReporting: To report result to file.
So each class has its own responsibility, here’s the advantages of this improvement:
- Easy to understand classes.
- Easy to maintain.
- Easy to reuse classes in other applications.
- Low coupling:
What happen if data exist in database not in file, in our last design our application is high coupled with file provider.
Using interfaces and abstract classes improve the low coupling, and the question is which type to use interface or abstract class?
Interface permit to define a conract without implementation, so no behavior logic exist for interfaces,however abstract classes let you define some default behaviors; and they force your subclasses to provide others.
Even you choose to use abstract class to define a default behavior, it’s better to provide also an interface, to disociate between the contract and the behaviour, this decoupling makes the code more flexible, and any changes in the behaviour will not impact a lot of your code if you use interfaces.
Let’s add an interface that provide methods to get data from anywhere , and for the case of file we need class that implement this interface.
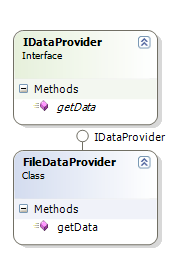
And FileProvider inherit from IDataProvider to implement getData, and the same design can be used for DataProcessing and ReportResult.
Here’s the new collaboration between classes after refactoring:
Here’s the new collaboration between classes after refactoring:
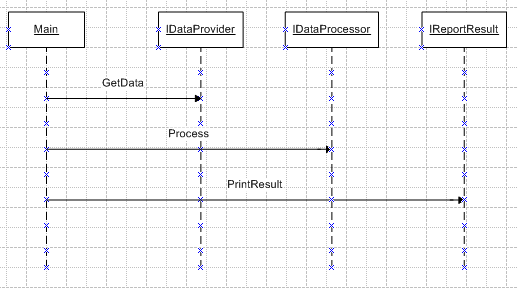
- Class Factory:
In the latest design the creation of concrete instances of IDataProvider,IDataProcessing and IReportResult are created by Main method.
To improve the cohesion it’s better to assign this responsibility to a factory class so a logic to instanciate a family of instances needed is isolated.
- Controller:
The orchestration between all classes is implemented in the main method.
To imporve the cohesion let’s assign this responsability to a Controller class, so we can use it in other applications.
The controller needs three classes to interact with them, controller could instatiate directly objects needed, but to improve low coupling, it’s better to give to the controller the objects needed.
For that two approachs could be used:
In house approach:
For this approach two main solutions exist:
- Add method named BindInstances(IDataProviderPtr,IDataProcesingPtr,IReportResultPtr).
- Use generics so the controller will be instantiated like that:
Controller<FileProvider,DataProcessor,ConsoleReport>
The difference between the two solutions is that for the first one each DataProvider must inherit from IDataProvider, and for the second one FileProvider need only the method GetData() even if it’s inherit from another class than IDataProvider.
The second choice is more decoupled than the first one, I dont need to inherit from IDataProvider, generics are a powerful tool to make the code more flexible.
Using DI frameworks aproach:
Another popular approach is to use a dependency injection framework like spring, guice or picocontainer to did the job.
Here’s the new collaboration between classes after refactoring:
In the latest design the creation of concrete instances of IDataProvider,IDataProcessing and IReportResult are created by Main method.
To improve the cohesion it’s better to assign this responsibility to a factory class so a logic to instanciate a family of instances needed is isolated.
- Controller:
The orchestration between all classes is implemented in the main method.
To imporve the cohesion let’s assign this responsability to a Controller class, so we can use it in other applications.
The controller needs three classes to interact with them, controller could instatiate directly objects needed, but to improve low coupling, it’s better to give to the controller the objects needed.
For that two approachs could be used:
In house approach:
For this approach two main solutions exist:
- Add method named BindInstances(IDataProviderPtr,IDataProcesingPtr,IReportResultPtr).
- Use generics so the controller will be instantiated like that:
Controller<FileProvider,DataProcessor,ConsoleReport>
The difference between the two solutions is that for the first one each DataProvider must inherit from IDataProvider, and for the second one FileProvider need only the method GetData() even if it’s inherit from another class than IDataProvider.
The second choice is more decoupled than the first one, I dont need to inherit from IDataProvider, generics are a powerful tool to make the code more flexible.
Using DI frameworks aproach:
Another popular approach is to use a dependency injection framework like spring, guice or picocontainer to did the job.
Here’s the new collaboration between classes after refactoring:
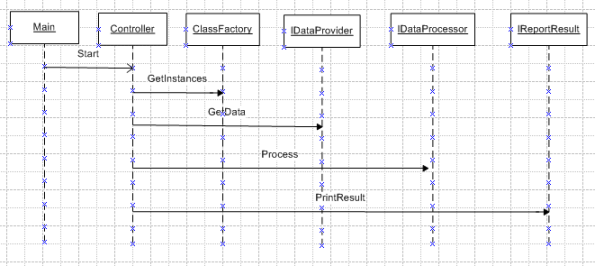
Benefit of refactoring:
After refactoring using the two principles,this application became more flexible and we can use it for different scenario:
- Can get data from file,database,xml file,csv file,…
- Can process with many class not only one.
- Can report to console,file,….
Source : http://javadepend.wordpress.com/2011/12/12/two-poweful-principles-to-improve-the-design/#more-336
J2EE clustering
Enterprises are choosing Java 2, Enterprise Edition (J2EE) to deliver their mission-critical applications over the Web. Within the J2EE framework, clusters provide mission-critical services to ensure minimal downtime and maximum scalability. A cluster is a group of application servers that transparently run your J2EE application as if it were a single entity. To scale, you should include additional machines within the cluster. To minimize downtime, make sure every component of the cluster is redundant.
In this article we will gain a foundational understanding of clustering, clustering methods, and important cluster services. Because clustering approaches vary across the industry, we will examine the benefits and drawbacks of each approach. Further, we will discuss the important cluster-related features to look for in an application server.
To apply our newly acquired clustering knowledge to the real world, we will see how HP Bluestone Total-e-Server 7.2.1, Sybase Enterprise Application Server 3.6, SilverStream Application Server 3.7, and BEA WebLogic Server 6.0 each implement clusters.
In Part 2 of this series, we will cover programming and failover strategies for clusters, as well as test our four application server products to see how they scale and failover.
Clusters defined
J2EE application server vendors define a cluster as a group of machines working together to transparently provide enterprise services (support for JNDI, EJB, JSP, HttpSession and component failover, and so on). They leave the definition purposely vague because each vendor implements clustering differently. At one end of the spectrum rest vendors who put a dispatcher in front of a group of independent machines, none of which has knowledge of the other machines in the cluster. In this scheme, the dispatcher receives an initial request from a user and replies with an HTTP redirect header to pin the client to a particular member server of the cluster. At the other end of the spectrum reside vendors who implement a federation of tightly integrated machines, with each machine totally aware of the other machines around it along with the objects on those machines.
In addition to machines, clusters can comprise redundant and failover-capable:
Regardless of how they are implemented, all clusters provide two main benefits: scalability and high availability (HA).
Scalability
Scalability refers to an application's ability to support increasing numbers of users. Clusters allow you to provide extra capacity by adding extra servers, thus ensuring scalability.
High availability
HA can be summed up in one word: redundancy. A cluster uses many machines to service requests. Therefore, if any machine in a cluster fails, another machine can transparently take over.
A cluster only provides HA at the application server tier. For a Web system to exhibit true HA, it must be like Noah's ark in containing at least two of everything, including Web servers, gateway routers, switching infrastructures, and so on. (For more on HA, see the HA Checklist.)
Cluster types
J2EE clusters usually come in two flavors: shared nothing and shared disk. In a shared-nothing cluster, each application server has its own filesystems with its own copy of applications running in the cluster. Application updates and enhancements require updates in every node in the cluster. With this setup, large clusters become maintenance nightmares when code pushes and updates are released.
In contrast, a shared-disk cluster employs a single storage device that all application servers use to obtain the applications running in the cluster. Updates and enhancements occur in a single filesystem and all machines in the cluster can access the changes. Until recently, a downside to this approach was its single point of failure. However, SAN gives a single logical interface into a redundant storage medium to provide failover, failback, and scalability. (For more on SAN, see the Storage Infrastructure sidebar.)
When comparing J2EE application servers' cluster implementations, it's important to consider:
Cluster implementation
J2EE application servers implement clustering around their implementation of JNDI (Java Naming and Directory Interface). Although JNDI is the core service J2EE applications rely on, it is difficult to implement in a cluster because it cannot bind multiple objects to a single name. Three general clustering methods exist in relation to each application server's JNDI implementation:
HP Bluestone Total-e-Server and SilverStream Application Server utilize an independent JNDI tree for each application server. Member servers in an independent JNDI tree cluster do not know or care about the existence of other servers in the cluster. Therefore, failover is either not supported or provided through intermediary services that redirect HTTP or EJB requests. These intermediary services are configured to know where each component in the cluster resides and how to get to an alternate component in case of failure.
One advantage of the independent JNDI tree cluster: shorter cluster convergence and ease of scaling. Cluster convergence measures the time it takes for the cluster to become fully aware of all the machines in the cluster and their associated objects. However, convergence is not an issue in an independent JNDI tree cluster because the cluster achieves convergence as soon as two machines start up. Another advantage of the independent JNDI tree cluster: scaling requires only the addition of extra servers.
However, several weaknesses exist. First, failover is usually the developer's responsibility. That is, because each application server's JNDI tree is independent, the remote proxies retrieved through JNDI are pinned to the server on which the lookup occurred. Under this scenario, if a method call to an EJB fails, the developer has to write extra code to connect to a dispatcher, obtain the address of another active server, do another JNDI lookup, and call the failed method again. Bluestone implements a more complicated form of the independent JNDI tree by making every request go through an EJB proxy service or Proxy LBB (Load Balance Broker). The EJB proxy service ensures that each EJB request goes to an active UBS instance. This scheme adds extra latency to each request but allows automatic failover in between method calls.
Centralized JNDI tree
Sybase Enterprise Application Server implements a centralized JNDI tree cluster. Under this setup, centralized JNDI tree clusters utilize CORBA's CosNaming service for JNDI. Name servers house the centralized JNDI tree for the cluster and keep track of which servers are up. Upon startup, every server in the cluster binds its objects into its JNDI tree as well as all of the name servers.
Getting a reference to an EJB in a centralized JNDI tree cluster is a two-step process. First, the client looks up a home object from a name server, which returns an interoperable object reference (IOR). An IOR points to several active machines in the cluster that have the home object. Second, the client picks the first server location in the IOR and obtains the home and remote. If there is a failure in between EJB method invocation, the CORBA stub implements logic to retrieve another home or remote from an alternate server listed in the IOR returned from the name server.
The name servers themselves demonstrate a weakness of the centralized JNDI tree cluster. Specifically, if you have a cluster of 50 machines, of which five are name servers, the cluster becomes useless if all five name servers go down. Indeed, the other 45 machines could be up and running but the cluster will not serve a single EJB client while the naming servers are down.
Another problem arises from bringing an additional name server online in the event of a total failure of the cluster's original name servers. In this case, a new centralized name server requires every active machine in the cluster to bind its objects into the new name server's JNDI tree. Although it is possible to start receiving requests while the binding process takes place, this is not recommended, as the binding process prolongs the cluster's recovery time. Furthermore, every JNDI lookup from an application or applet really represents two network calls. The first call retrieves the IOR for an object from the name server, while the second retrieves the object the client wants from a server specified in the IOR.
Finally, centralized JNDI tree clusters suffer from an increased time to convergence as the cluster grows in size. That is, as you scale your cluster, you must add more name servers. Keep in mind that the generally accepted ratio of name server machines to total cluster machines is 1:10, with a minimum number of two name servers. Therefore, if you have a 10-machine cluster with two name servers, the total number of binds between a server and name server is 20. In a 40-machine cluster with four name servers, there will be 160 binds. Each bind represents a process wherein a member server binds all of its objects into the JNDI tree of a name server. With that in mind, the centralized JNDI tree cluster has the worst convergence time among all of the JNDI cluster implementations.
Shared global JNDI tree
Finally, BEA WebLogic implements a shared global JNDI tree. With this approach, when a server in the cluster starts up it announces its existence and JNDI tree to the other servers in the cluster through IP (Internet Protocol) multicast. Each clustered machine binds its objects into the shared global JNDI tree as well as its own local JNDI tree.
Having a global and local JNDI tree within each member server allows the generated home and remote stubs to failover and provides quick in-process JNDI lookups. The shared global JNDI tree is shared among all machines within the cluster, allowing any member machine to know the exact location of all objects within the cluster. If an object is available at more than one server in the cluster, a special home object is bound into the shared global JNDI tree. This special home knows the location of all EJB objects with which it is associated and generates remote objects that also know the location of all EJB objects with which it is associated.
The shared global approach's major downsides: the large initial network traffic generated when the servers start up and the cluster's lengthy convergence time. In contrast, in an independent JNDI tree cluster, convergence proves not to be an issue because no JNDI information sharing occurs. However, a shared global or centralized cluster requires time for all of the cluster's machines to build the shared global or centralized JNDI tree. Indeed, because shared global clusters use multicast to transfer JNDI information, the time required to build the shared global JNDI tree is linear in relation to the number of subsequent servers added.
The main benefits of shared global compared with centralized JNDI tree clusters center on ease of scaling and higher availability. With shared global, you don't have to fiddle with the CPUs and RAM on a dedicated name server or tune the number of name servers in the cluster. Rather, to scale the application, just add more machines. Moreover, if any machine in the cluster goes down, the cluster will continue to function properly. Finally, each remote lookup requires a single network call compared with the two network calls required in the centralized JNDI tree cluster.
All of this should be taken with a grain of salt because JSPs, servlets, EJBs, and JavaBeans running on the application server can take advantage of being co-located in the EJB server. They will always use an in-process JNDI lookup. Keep in mind that if you run only server-side applications, little difference exists among the independent, centralized, or shared global cluster implementations. Indeed, every HTTP request will end up at an application server that will do an in-process JNDI lookup to return any object used within your server-side application.
Next, we turn our attention to the second important J2EE application server consideration: cluster and failover services.
Cluster and failover services
Providing J2EE services on a single machine is trivial compared with providing the same services across a cluster. Due to the complications of clustering, every application server implements clustered components in unique ways. You should understand how vendors implement clustering and failover of entity beans, stateless session beans, stateful session beans, and JMS. Many vendors claim to support clustered components but their definitions of what that means usually involve components running in a cluster. For example, BEA WebLogic Server 5.1 supported clustered stateful session beans but if the server that the bean instance was on were to fail, all of the state would be lost. The client would then have to re-create and repopulate the stateful session bean, making it useless in a cluster. It wasn't until BEA WebLogic 6.0 that stateful session beans employed in-memory replication for failover and clustering.
All application servers support EJB clustering but vary greatly in their support of configurable automatic failover. Indeed, some application servers do not support automatic failover in any circumstance by EJB clients. For example, Sybase Enterprise Application Server supports stateful session bean failover if you load the bean's state from a database or serialization. As mentioned above, BEA WebLogic 6.0 supports stateful session bean failover through in-memory replication of stateful session bean state. Most application servers can have JMS running in a cluster but don't have load balancing or failover of individually named Topics and Queues. With that in mind, you'll probably need to purchase a clusterable implementation of JMS such as SonicMQ to get load balancing to Topics and Queues.
Another important consideration, to which we now turn our attention: HttpSession failover.
HttpSession failover
HttpSession failover allows a client to seamlessly get session information from another server in the cluster when the original server on which the client established a session fails. BEA WebLogic Server implements in-memory replication of session information, while HP Bluestone Total-e-Server utilizes a centralized session server with a backup for HA. SilverStream Application Server and Sybase Enterprise Application Server utilize a centralized database or filesystem that all application servers would read and write to.
The main drawback of database/filesystem session persistence centers around limited scalability when storing large or numerous objects in the HttpSession. Every time a user adds an object to the HttpSession, all of the objects in the session are serialized and written to a database or shared filesystem. Most application servers that utilize database session persistence advocate minimal use of the HttpSession to store objects, but this limits your Web application's architecture and design, especially if you are using the HttpSession to store cached user data.
Memory-based session persistence stores session information in-memory to a backup server. Two variations of this method exist. The first method writes HttpSession information to a centralized state server. All machines in the cluster write their HttpSession objects to this server. In the second method, each cluster node chooses an arbitrary backup node to store session information in-memory. Each time a user adds an object to the HttpSession, that object alone is serialized and added in-memory to a backup server.
Under these methods, if the number of servers in the cluster is low, the dedicated state server proves better than in-memory replication to an arbitrary backup server because it frees up CPU cycles for transaction processing and dynamic page generation.
On the other hand, when the number of machines in the cluster is large, the dedicated state server becomes the bottleneck and in-memory replication to an arbitrary backup server (versus a dedicated state server) will scale linearly as you add more servers. In addition, as you add more machines to the cluster you will need to constantly tune the state server by adding more RAM and CPUs. With in-memory replication to an arbitrary backup server, you just add more machines and the sessions evenly distribute themselves across all machines in the cluster. Memory-based persistence provides flexible Web application design, scalability, and high availability.
Now that we've tackled HttpSession failover, we will examine single points of failure.
Single points of failure
Cluster services without backup are known as single points of failure. They can cause the whole cluster or parts of your application to fail. For example, WebLogic JMS can have only a Topic running on a single machine within the cluster. If that machine happens to go down and your application relies on JMS Topics, your cluster will be down until another WebLogic instance is started with that JMS Topic. (Note that only durable messages will be delivered when the new instance is started.)
Ask yourself if your cluster has any single points of failure. If it does, you will need to gauge whether or not you can live with them based on your application requirements.
Next up, flexible scaling topologies.
Flexible scaling topologies
Clustering also requires a flexible layout of scaling topologies. Most application servers can take on the responsibilities of an HTTP server as well as those of an application server, as seen in Figure 1.
The architecture illustrated in Figure 1 is good if most of your Website serves dynamic content. However, if your site serves mostly static content, then scaling the site would be an expensive proposition, as you would have to add more application servers to serve static HTML page requests. With that in mind, to scale the static portions of your Website, add Web servers; to scale the dynamic portions of your site, add application servers, as in Figure 2.
The main drawback of the architecture shown in Figure 2: added latency for dynamic pages requests. However, it provides a flexible methodology for scaling static and dynamic portions of the site independently.
Finally, what application server discussion would be complete without a look at maintenance?
Maintenance
With a large number of machines in a cluster, maintenance revolves around keeping the cluster running and pushing out application changes. Application servers should provide agents to sense when critical services fail and then restart them or activate them on a backup server. Further, as changes and updates occur, an application server should provide an easy way to update and synchronize all servers in the cluster.
Sybase Enterprise Application Server and HP Bluestone Total-e-Server provide file and configuration synchronization services for clusters. Sybase Enterprise Application Server provides file and configuration synchronization services at the host, group, or cluster level. Bluestone offers file and configuration synchronization services only at the host level. If large applications as well as numerous changes need to be deployed, this process will take a long time. BEA WebLogic Server provides configuration synchronization only. Of the two, configuration synchronization with a storage area network works better because changes can be made to a single logical storage medium and all of the machines in the cluster will receive the application file changes. Each machine then only has to receive configuration changes from a centralized configuration server. SilverStream Application server loads application files and configuration from a database using dynamic class loaders. The dynamic class loaders facilitate application changes in a running application server.
That concludes our look at the important features to consider in application servers. Next let's look at how our four popular application servers handle themselves in relation to our criteria.
Application server comparisons
Now that we have talked about clusters in general, let's focus our attention upon individual application servers and apply what we learned to the real world. Below, you'll find comparisons of:
Each application server section provides a picture of an HA architecture followed by a summary of important features as presented in this article.
HP Bluestone Total-e-Server 7.2.1
General cluster summary:
Bluestone implements independent JNDI tree clustering. An LBB, which runs as a plug-in within a Web server, provides load balancing and failover of HTTP requests. LBBs know which applications are running on which UBS (universal business server) instance and can direct traffic appropriately. Failover of stateful and stateless session and entity beans is supported in between method calls through EJB Proxy Service and Proxy LBB. The main disadvantages of EJB Proxy Service are that it adds extra latency to each EJB request and it runs on the same machine as the UBS instances. The EJB Proxy Service and UBS stubs allow failover in case of UBS instance failure but do not allow failover in case of hardware failure. Hardware failover is supported through client-side configuration of apserver.txt or Proxy LBB configuration of apserver.txt. The client-side apserver.txt lists all of the components in the cluster. When additional components are added to the cluster, all clients need to be updated through the BAM (Bluestone Application Manager) or manually on a host-by-host basis. Configuring apserver.txt on the Proxy LBB insulates clients from changes in the cluster but again adds additional latency to each EJB call. HP Bluestone is the only application server to provide clustered and load-balanced JMS.
Cluster convergence time:
Least, when compared with centralized and shared global JNDI tree clusters.
HttpSession failover:
In-memory centralized state server and backup state server or database.
Single points of failure:
None.
Flexible cluster topology:
All clustering topologies are supported.
Maintenance:
Bluestone excels at maintenance. Bluestone provides a dynamic application launcher (DAL) that the LBB calls when an application or machine is down. The DAL can restart applications on the primary or backup machine. In addition, Bluestone provides a configuration and deployment tool called Bluestone Application Manager (BAM), which can deploy application packages and their associated configuration files. The single downside of this tool is that you can configure only one host at a time -- problematic for large clusters.
Sybase Enterprise Application Server 3.6
General cluster summary:
Enterprise Application Server implements centralized JNDI tree clustering, and a hardware load balancer provides load balancing and failover of HTTP requests. The two name servers per cluster can handle HTTP requests, but for performance considerations they typically should be dedicated exclusively to handling JNDI requests.
Enterprise Application Server 3.6 does not have Web server plug-ins; they will, however, be available with the EBF (Error and Bug Fixes) for 3.6.1 in February. The application supports stateful and stateless session and entity bean failover in between method calls. Keep in mind that Enterprise Application Server does not provide any monitoring agents or dynamic application launchers, requiring you to buy a third-party solution like Veritas Cluster Server for the single points of failure or automatic server restarts. Enterprise Application Server does not support JMS.
Cluster convergence time:
Convergence time depends on the number of name servers and member servers in the cluster. Of the three cluster implementations, centralized JNDI tree clusters produce the worst convergence times. Although convergence time is important, member machines can start receiving requests after binding objects into a name server that is utilized by an EJB client (this is not recommended, however).
HttpSession failover:
HttpSession failover occurs through a centralized database. There's no option for in-memory replication.
Single points of failure:
No single points of failure exist if running multiple name servers.
Flexible cluster topology:
A flexible cluster topology is limited due to the lack of Web server plug-ins.
Maintenance:
Sybase provides the best option for application deployment through a file and configuration synchronization. It can synchronize clusters at the component, package, servlet, application, or Web application level. You can also choose to synchronize a cluster, group of machines, or individual host -- an awesome feature but it can take a while if there are many machines in the cluster and many files to add or update. A weakness is the lack of dynamic application launching services, which means you must purchase a third-party solution such as Veritas Cluster Server.
SilverStream Application Server 3.7
General cluster summary:
When setting up a SilverStream cluster, choose from two configurations: dispatcher-based or Web server integration-module (WSI)-based. In a dispatcher-based cluster, a user connects to the dispatcher or hardware-based dispatcher -- Alteon 180e, for example. Then the dispatcher sends an HTTP redirect to pin the client to a machine in the cluster. From that point on, the client is physically bound to a single server. In the dispatcher configuration there is no difference between a single machine and cluster because, as far as the client is concerned, the cluster becomes a single machine. The major disadvantage: you can't scale the static portions of the site independently of the dynamic portions.
In a WSI-based cluster, a user connects to a dispatcher, which load balances and failovers HTTP requests to Web servers. Each Web server has a plug-in that points to a load balancer fronting a SilverStream cluster. The WSI cluster does not use redirection, so every HTTP request is load balanced across any of the Web servers. The secondary load balancer insures failover at the application server tier. A WSI architecture advantage over the dispatcher architecture: the ability to independently scale static and dynamic portions of a site. In a major disadvantage, the ArgoPersistenceManager is required for HttpSession failover. In either architecture, EJB clients still cannot failover in between method calls. EJB failover totally remains the developer's responsibility. Finally, SilverStream does not support clustered JMS.
HttpSession failover:
SilverStream provides HttpSession failover by a centralized database and the ArgoPersistenceManager. The solution, unfortunately, is proprietary. Instead of using the standard HttpSession to store session information to a database, you must use the product's ArgoPersistenceManager class -- a drawback.
Cluster convergence time:
Least, when compared with centralized and shared global JNDI tree clusters.
Single points of failure:
None with the above architectures.
Flexible cluster topology:
All clustering topologies supported.
Maintenance:
Cache manager and dynamic class-loaders provide an easy way to deploy and upgrade running applications with little interruption to active clients. When an application is updated on one server in the cluster, the update gets written to a database and the cache manager invalidates the caches on all other servers, forcing them to refetch the updated parts of the application on next access. The only downside of this approach is the time needed to load applications out of the database and into active memory during the initial access.
BEA WebLogic Server 6.0
General cluster summary:
WebLogic Server implements clustering through a shared global JNDI cluster tree. Under this setup, when an individual server starts up it puts its JNDI tree into the shared global JNDI tree. The server then uses its copy of the tree to service requests, allowing an individual server to know the exact location of all objects in the cluster. Stubs that clients utilize are cluster-aware, meaning that they are optimized to work on their server of origin but also possess knowledge of all other replica objects running in different application servers. Because clusterable stubs have knowledge of all replica objects in the cluster, they can transparently failover to other replica objects in the cluster. A unique feature of WebLogic Server is in-memory replication of stateful session beans as well as configurable automatic failover of EJB remote objects. WebLogic defines clusterable as a service that can run in a cluster. JMS is clusterable but each Topic or Queue only runs on a single server within the cluster. You cannot load balance or failover JMS Topics or Queues in a cluster -- a major weakness of WebLogic's JMS implementation.
HttpSession failover:
WebLogic Server provides HttpSession failover by transparent in-memory state replication to an arbitrary backup server or database server. Every machine in the cluster picks a different backup machine. If the primary server fails, the backup becomes a primary and the primary picks a new backup server. A unique feature of WebLogic is cookie independence. Both HP Bluestone and Enterprise Application Server require cookies for HttpSession failover. WebLogic can use encrypted information in the URL to direct a client to the backup server if there is a failure.
Single points of failure:
JMS and Administration server.
Flexible cluster topology:
All clustering topologies supported.
Maintenance:
WebLogic's weakness is maintenance. Although BEA has made positive steps with configuration synchronization, WebLogic Server does not provide any monitoring agents, dynamic application launchers, or file synchronization services. This shortfall requires you to buy a third-party solution for the single points of failure or implement sneaker HA. With sneaker HA, all WebLogic Administrators have to wear Nike Air Streak Vapor IV racing shoes. If a server goes down they must sprint to the machine and troubleshoot the problem. However, if you employ SAN you don't need file synchronization services, but most developers are just beginning to realize the benefits of SAN.
Analysis
Overall BEA WebLogic Server 6.0 has the most robust and well thought-out clustering implementation. HP Bluestone Total-e-Server 2.7.1, Sybase Enterprise Application Server 3.6, and SilverStream Application Server 3.7 would be the next choices, in that order.
Picking the right application server entails making tradeoffs. If you are writing an application where you will have EJB clients (applets and applications), Web clients, extensive use of HttpSession (for caching), and ease of scaling and failover, you will want to go with BEA WebLogic 6.0. If your application requires heavy use of JMS and most of your clients are Web clients, Bluestone will probably be a better choice. From a clustering standpoint Sybase Enterprise Application Server 3.7 lacks important clustering features such as JMS, in-memory HttpSession replication, session-based server affinity, and partitioning through Web server plug-ins. Sybase Enterprise Application Server 3.7 does, however, bring to the table file and configuration synchronization services. But this benefit is minimized if you are using SAN. SilverStream Application Server has the weakest implementation of clustering and lacks clustered JMS, in-memory HttpSession replication, and failover.
Conclusion
In this article you have gained a foundational understanding of clustering, clustering methods, and important cluster services. We have examined the benefits and drawbacks of each application server and discussed the important cluster-related features to look for in an application server. With this knowledge, you now understand how to set up clusters for high availability and scalability. However, this represents just the beginning of your journey. Go out, get some evaluation clustering licenses, and Control-C some application servers.
In Part 2, we will start writing code, test the application server vendors' claims, and provide failover and cluster strategies for each of the different application servers. Further, we will use the J2EE Java Pet Store for load testing and cluster convergence benchmarks.
Part 2
Within the J2EE framework, clusters provide an infrastructure for high availability (HA) and scalability. A cluster is a group of application servers that transparently run your J2EE application as if the group were a single entity. However, Web applications behave differently when they are clustered as they must share application objects with other cluster members through serialization. Moreover, you'll have to contend with the extra configuration and setup time.
To avoid major Web application rework and redesign, you should from the very beginning of your development process consider cluster-related programming issues, as well as critical setup and configuration decisions in order to support intelligent load balancing and failover. Finally, you will need to have a management strategy to handle failures.
Read the whole "J2EE clustering" series:
Building on the information in Part 1, I'll impart an applied understanding of clustering. Further, I'll examine clustering-related issues and their possible solutions, as well as the advantages and disadvantages of each choice. I'll also demonstrate programming guidelines for clustering. Finally, I'll show you how to prepare for outages. (Note that, due to licensing constraints, this article will not cover benchmarking.)
Set up your cluster
During cluster setup, you need to make important decisions. First, you have to choose a load balancing method. Second, you must decide how to support server affinity. Finally, you need to determine how you will deploy the server instances among clustered nodes.
Load balancing
You can choose between two generally recognized options for load balancing a cluster: DNS (Domain Name Service) round robin or hardware load balancers.
DNS round robin
DNS is the process by which a logical name (i.e., www.javaworld.com) is converted to an IP address. In DNS round-robin load balancing, a single logical name can return any IP address of the machines in a cluster.
DNS round-robin load balancing's advantages include:
Hardware load balancers
In contrast, a hardware load balancer (like F5's Big IP) solves most of these problems through virtual IP addressing. A load balancer presents to the world a single IP address for the cluster. The load balancer receives each request and rewrites headers to point to other machines in the cluster. If you remove any machine in the cluster, the changes take effect immediately.
Hardware load balancers' advantages include:
However, hardware load balancers exhibit disadvantages:
Once you have picked your load balancing scheme, you must decide how your cluster will support server affinity.
Server affinity
Server affinity becomes a problem when using SSL without Web server proxies. (Server affinity directs a user to a particular server in the cluster for the duration of her session.) Hardware load balancers rely on cookies or URL readings to determine where requests are directed. If requests are SSL encrypted, hardware load balancers cannot read the header, cookie, or URL information. To solve the problem, you have two choices: Web server proxies or SSL accelerators.
Web server proxies
In this scenario, a hardware load balancer acts like a DNS load balancer for the Web server proxies, except that it acts through a single IP address. The Web servers decrypt SSL requests and pass them to the Web server plug-in (Web server proxy). Once the plug-in receives a decrypted request, it can parse the cookie or URL information and redirect the request to the application server where the user's session state resides.
With Web server proxies, the major advantages include:
The disadvantages are:
SSL accelerators
SSL accelerator networking hardware processes SSL requests to the cluster. It sits in front of the hardware load balancer, allowing the hardware load balancer to read decrypted information in cookies, headers, and URLs. The hardware load balancer can then use its own metrics to direct requests. With this setup, you can avoid Web proxies if you choose and still achieve server affinity through SSL.
With SSL accelerators, you benefit from:
The disadvantages comprise:
Application server distribution
When distributing application server instances throughout your cluster, you must decide whether or not you want multiple application server instances on single nodes in the cluster, and determine the total number of nodes in your cluster.
The number of application server instances on a single node depends on the number of CPUs on the box, CPU utilization, and available memory. Consider multiple instances on a single box in any of three situations:
Determining the optimal number of nodes in your cluster is an iterative process. First, profile and optimize the application. Second, use load-testing software to simulate your expected peak usage. Finally, add additional surplus nodes to handle the load when failures occur.
Ideally, it would be best to push out development releases to a staging cluster to catch clustering issues as they occur. Unfortunately, developers create most applications for a single machine, then migrate them to a clustered environment, a situation that can break the application.
Session-storage guidelines
To minimize the breakage, follow these general guidelines for application servers that use in-memory or database session persistence:
//You need this so the AccountModel object on the backup receives the
//Credit card
session.setAttribute("account",am);
... public class AccountWebImpl extends AccountModel implements ModelUpdateListener, HttpSessionBindingListener {
transient private Account acctEjb;
...
private void writeObject(ObjectOutputStream s) {
try {
s.defaultWriteObject(); Handle acctHandle = acctEjb.getHandle();
s.writeObject(acctHandle);
}
catch (IOException ioe) {
Debug.print(ioe);
throw new GeneralFailureException(ioe);
}
catch (RemoteException re) {
throw new GeneralFailureException(re);
}
}
private void readObject(ObjectInputStream s) {
try {
s.defaultReadObject();
Handle acctHandle = (Handle)s.readObject()
Object ref = acctHandle.getEJBObject();
acctEjb = (Account) PortableRemoteObject.narrow(ref,Account.class);
}
catch (ClassNotFoundException cnfe) {
throw new GeneralFailureException(cnfe);
}
catch (RemoteException re) {
throw new GeneralFailureException(re);
}
catch (IOException ioe) {
Debug.print(ioe);
throw new GeneralFailureException(ioe);
}
}
In-memory session ststate replication
In-memory session state replication proves more complicated than database persistence because individual objects in the HttpSession are serialized to a backup server as they change. With database session persistence, the objects in the session are serialized together when any one of them changes. As a side effect, in-memory session state replication clones all HttpSession objects stored directly under a session key. This has virtually no effect if each object stored under a session key is independent of the other objects stored under different session keys. However, if the objects stored under session keys are highly dependent on other objects within the HttpSession, copies will be made on the backup machine. After failing over, your application will continue to run but some features may not work -- a shopping cart may refuse to accept more items, for instance. The problem stems from different parts (updating the shopping cart and displaying the shopping cart) of your application referring to their own copies of the shopping cart object. The class responsible for updating the cart is making changes to its copy of the shopping cart while the JSPs attempt to display their copy of the shopping cart. In a single-server environment, this problem would not arise because both parts of your application would point to the same shopping cart.
Here is an example of indirectly copying objects:
import java.io.*;
public class Aaa implements Serializable {
String name;
pubic void setName (String name) {
this.name = name;
}
public String getName( ) {
return name;
}
}
import java.io.*;
public class Bbb implements Serializable {
Aaa a;
public Bbb (Aaa a) {
this.a = a;
}
pubic void setName (String name) {
a.setName(name);
}
public String getName( ) {
return a.getName();
}
}
In first.jsp on server1:
<%
Aaa a = new Aaa();
a.setName("Abe");
Bbb b = new Bbb(a);
// a is copied to backup machine under key "a"
session.setAttribute("a",a);
// b is copied to backup machine under key "b"
session.setAttribute("b",b);
%>
In second.jsp on server1:
<%
Bbb b = (Bbb)session.getAttribute("b");
b.setName("Bob");
// b is copied to backup machine under key "b"
// but object Aaa under key "a" has the name "Abe"
// and "b"'s Aaa has the name "Bob"
session.setAttribute("b",b);
---> Failure trying to get to server1's third.jsp
----->Failover to server2's (backup machine) third.jsp
In third.jsp on server2:
The name associated with Object Aaa is:
<%=((Aaa)session.getAttribute("a")).getName()%>
The name associated with Object Aaa through Object Bbb is:
<%=((Bbb)session.getAttribute("b")).getName()%>
...
//End of third.jsp
The first expression tag outputs "Abe", while the second expression tag outputs "Bob". On a single server, both expressions would output "Bob".
To see invalid session state copies, create a Cluster Object Relationship Diagram (CORD) like the figure below.
JavaPetStore CORD. Click on thumbnail to view full-size image.
In the diagram, the ovals represent objects directly stored under a key value in the HttpSession. The squares represent objects indirectly referenced by an object stored under an HttpSession key. The filled-in arrows point to objects that are the source object's instance variables. The open arrows indicate an inheritance relationship.
Counting the number of arrows pointing into an object usually tell you the number of copies of that object will be generated. If the arrow points to an oval, you have to add one to the total number of arrows because the oval is stored in the HttpSession under a session key. For example, look at the ContactInformation oval. It has one arrow pointing into it, indicating two copies: one stored directly under a session key and another stored as an instance variable of AccountWebImpl.
I say usually because complex relationships tend to bend this rule of thumb. Look at ShoppingClientControllerWebImpl; it has one arrow pointing into it, so there are two copies, right? Wrong! There are three copies: one through ModelManager, one through AccountWebImpl, and one through RequestProcessor. You cannot count ShoppingClientControllerWebImpl itself because it is not directly stored under an HttpSession key.
Let's try another example. How many copies of ModelManager are there? If you answered four, you are right. There is a copy from ModelManager itself because it is stored under an HttpSession key, AccountWebImpl, ShoppingCartWebImpl, and RequestProcessor. I didn't count the arrow from RequestToEventTranslator because it is not directly stored under an HttpSession key, and its reference to ModelManager is the same as the reference from RequestProcessor.
Note: With in-memory replication, always remember: any object stored under an HttpSession key will be cloned and sent to the backup machine.
To keep multiple object copies to a minimum, store primitive object types, simple objects, or independent objects under session keys in HttpSession. If you can't avoid having complex interrelated objects in the HttpSession, use session.setAttribute(...) to remove copies once the user has failed over. For example, to replace the clone of ModelManager in AccountWebImpl with the real ModelManager, you need to call session.setAttribute("account",accountWebImplWithRealModelManager). In most cases, you will focus your analysis to copied objects with shared state. If the object doesn't have any shared instance variables, you can leave it alone. The single side effect: increased memory usage for every client that fails over. After testing proves that everything fails over properly in your cluster, you need to develop a cluster management strategy.
A cluster management strategy document defines what can go wrong and how to solve the problems. Generally, there are four categories of problems:
Since this is JavaWorld, I will focus on software. You will probably want to discuss the other issues with your local sysadmin, network admin, and DBA, respectively.
If software on a machine in a cluster fails, other cluster members must assume responsibility for the downed server, a process known as failover. In JSP applications, failover occurs at the Web proxy or hardware load balancer. For example, a request comes into the Web proxy, which notices the server it is trying to reach is down, so it sends the request to another application server. This application server activates the users' backup session state and fulfills the request. In an EJB client application, the remote references try different servers in the cluster until they receive a response.
This description makes failover seem trivial, but we have covered only the best-case scenario in which a failure occurs between requests. Failover proves more difficult when a failure occurs during a request. Let's take a look at examples involving JSPs and EJBs.
For our JSP example, imagine a user placing an order on your Website. When the user clicks the Submit button, the page seems to hang, and then he receives a message that reads "Response contained no data." In this situation, one of two things could have happened. The order may have completed but the server failed before delivering the response page. On the other hand, the server may have failed before saving the order and sending the response. Does the proxy automatically call the same URL on another server and reinitiate the transaction, causing possible duplicates? Or does it return an error and force the user to contact a member of your support team?
In our EJB example, imagine a user modifying inventory on a standalone Java application. Once the user clicks the Save button, a request reaches an EJB, but the application returns a RemoteException. Again, one of two things could have happened. The inventory could have been saved, but the server may have failed before delivering a reply. Or, the server could have failed before making inventory changes. Should the EJB remote automatically reattempt the same remote call on another server in the cluster and risk duplicates or inconsistent data?
After trying different failover techniques, I concluded that responsibility for transparent failover rests with the application server. You can try to use transaction tables or transaction identifiers in cookies, but the pain-to-gain ratio doesn't justify either. The simplest solution: after a server failure, run a set of stored procedures that find inconsistencies within the database and notify the interested parties.
Wrap it all up
This article has given you an applied understanding of clustering. You've learned how to set up, program for, and maintain J2EE clusters. You've seen the issues related to clustering, as well as possible solutions. With this practical knowledge, you can set up a working J2EE cluster.
But your work is not done: you have to develop the network, hardware, and database infrastructure to ensure HA. The easiest way to develop these services is through an enterprise hosting service. Most enterprise hosting services will set up your redundant networking, database, and hardware services. You just provide the clusterable code. Good luck and happy clustering.
Source: http://www.javaworld.com/jw-02-2001/jw-0223-extremescale.html?page=1#
http://www.javaworld.com/jw-08-2001/jw-0803-extremescale2.html?page=1
Non-Functional Requirements - Minimal Checklist
All IT systems at some point in their lifecycle need to consider non-functional requirements and their testing. For some projects these requirements warrant extensive work and for other project domains a quick check through may be sufficient. As a minimum, the following list can be a helpful reminder to ensure you have covered the basics. Based on your own project characteristics, I would recommend the topics are converted into SMART (Specific, Measurable, Attainable, Realisable, Timeboxed / Traceable) requirements with the detail and rigour appropriate to your project.
The list is also available at the bottom of the article as a one-page PDF document. While it is easy to make the list longer by adding more items, I would really like to hear how to make the list better while keeping it on one page (and readable) to share with other visitors here.
Security
• Login requirements - access levels, CRUD levels
• Password requirements - length, special characters, expiry, recycling policies
• Inactivity timeouts – durations, actions
Audit
• Audited elements – what business elements will be audited?
• Audited fields – which data fields will be audited?
• Audit file characteristics - before image, after image, user and time stamp, etc
Performance
• Response times - application loading, screen open and refresh times, etc
• Processing times – functions, calculations, imports, exports
• Query and Reporting times – initial loads and subsequent loads
Capacity
• Throughput – how many transactions per hour does the system need to be able to handle?
• Storage – how much data does the system need to be able to store?
• Year-on-year growth requirements
Availability
• Hours of operation – when is it available? Consider weekends, holidays, maintenance times, etc
• Locations of operation – where should it be available from, what are the connection requirements?
Reliability
• Mean Time Between Failures – What is the acceptable threshold for down-time? e.g. one a year, 4,000 hours
• Mean Time To Recovery – if broken, how much time is available to get the system back up again?
Integrity
• Fault trapping (I/O) – how to handle electronic interface failures, etc
• Bad data trapping - data imports, flag-and-continue or stop the import policies, etc
• Data integrity – referential integrity in database tables and interfaces
• Image compression and decompression standards
Recovery
• Recovery process – how do recoveries work, what is the process?
• Recovery time scales – how quickly should a recovery take to perform?
• Backup frequencies – how often is the transaction data, set-up data, and system (code) backed-up?
• Backup generations - what are the requirements for restoring to previous instance(s)?
Compatibility
• Compatibility with shared applications – What other systems does it need to talk to?
• Compatibility with 3rd party applications – What other systems does it have to live with amicably?
• Compatibility on different operating systems – What does it have to be able to run on?
• Compatibility on different platforms – What are the hardware platforms it needs to work on?
Maintainability
• Conformance to architecture standards – What are the standards it needs to conform to or have exclusions from?
• Conformance to design standards – What design standards must be adhered to or exclusions created?
• Conformance to coding standards – What coding standards must be adhered to or exclusions created?
Usability
• Look and feel standards - screen element density, layout and flow, colours, UI metaphors, keyboard shortcuts
• Internationalization / localization requirements – languages, spellings, keyboards, paper sizes, etc
Documentation
• Required documentation items and audiences for each item
Ten advantages of an ORM (Object Relational Mapper)
Here's a list of ten reasons why you should consider an ORM tool. Now not all ORMs are created equal, but these are key features that a first class ORM will handle for you.
1. Facilitates implementing the Domain Model pattern (Thanks Udi). This one reason supercedes all others. In short using this pattern means that you model entities based on real business concepts rather than based on your database structure. ORM tools provide this functionality through mapping between the logical business model and the physical storage model.
2. Huge reduction in code. ORM tools provide a host of services thereby allowing developers to focus on the business logic of the application rather than repetitive CRUD (Create Read Update Delete) logic.
3. Changes to the object model are made in one place. One you update your object definitions, the ORM will automatically use the updated structure for retrievals and updates. There are no SQL Update, Delete and Insert statements strewn throughout different layers of the application that need modification.
4. Rich query capability. ORM tools provide an object oriented query language. This allows application developers to focus on the object model and not to have to be concerned with the database structure or SQL semantics. The ORM tool itself will translate the query language into the appropriate syntax for the database.
5. Navigation. You can navigate object relationships transparently. Related objects are automatically loaded as needed. For example if you load a PO and you want to access it's Customer, you can simply access PO.Customer and the ORM will take care of loading the data for you without any effort on your part.
6. Data loads are completely configurable allowing you to load the data appropriate for each scenario. For example in one scenario you might want to load a list of POs without any of it's child / related objects, while in other scenarious you can specify to load a PO, with all it's child LineItems, etc.
7. Concurrency support. Support for multiple users updating the same data simultaneously.
8. Cache managment. Entities are cached in memory thereby reducing load on the database.
9. Transaction management and Isolation. All object changes occur scoped to a transaction. The entire transaction can either be committed or rolled back. Multiple transactions can be active in memory in the same time, and each transactions changes are isolated form on another.
10. Key Management. Identifiers and surrogate keys are automatically propogated and managed.
source :http://blogs.msdn.com/b/gblock/archive/2006/10/26/ten-advantages-of-an-orm.aspx
After refactoring using the two principles,this application became more flexible and we can use it for different scenario:
- Can get data from file,database,xml file,csv file,…
- Can process with many class not only one.
- Can report to console,file,….
Source : http://javadepend.wordpress.com/2011/12/12/two-poweful-principles-to-improve-the-design/#more-336
J2EE clustering
Enterprises are choosing Java 2, Enterprise Edition (J2EE) to deliver their mission-critical applications over the Web. Within the J2EE framework, clusters provide mission-critical services to ensure minimal downtime and maximum scalability. A cluster is a group of application servers that transparently run your J2EE application as if it were a single entity. To scale, you should include additional machines within the cluster. To minimize downtime, make sure every component of the cluster is redundant.
In this article we will gain a foundational understanding of clustering, clustering methods, and important cluster services. Because clustering approaches vary across the industry, we will examine the benefits and drawbacks of each approach. Further, we will discuss the important cluster-related features to look for in an application server.
To apply our newly acquired clustering knowledge to the real world, we will see how HP Bluestone Total-e-Server 7.2.1, Sybase Enterprise Application Server 3.6, SilverStream Application Server 3.7, and BEA WebLogic Server 6.0 each implement clusters.
In Part 2 of this series, we will cover programming and failover strategies for clusters, as well as test our four application server products to see how they scale and failover.
Clusters defined
J2EE application server vendors define a cluster as a group of machines working together to transparently provide enterprise services (support for JNDI, EJB, JSP, HttpSession and component failover, and so on). They leave the definition purposely vague because each vendor implements clustering differently. At one end of the spectrum rest vendors who put a dispatcher in front of a group of independent machines, none of which has knowledge of the other machines in the cluster. In this scheme, the dispatcher receives an initial request from a user and replies with an HTTP redirect header to pin the client to a particular member server of the cluster. At the other end of the spectrum reside vendors who implement a federation of tightly integrated machines, with each machine totally aware of the other machines around it along with the objects on those machines.
In addition to machines, clusters can comprise redundant and failover-capable:
- Load balancers: Single points of entry into the cluster and traffic directors to individual Web or application servers
- Web servers
- Gateway routers: Exit points out of an internal network
- Multilayer switches: Packet and frame filters to ensure that each machine in the cluster receives only information pertinent to that machine
- Firewalls: Cluster protectors from hackers by filtering port-level access to the cluster and internal network
- SAN (Storage Area Networking) switches: Connect the application servers, Web servers, and databases to a backend storage medium; manage which physical disk to write data to; and failover
- Databases
Regardless of how they are implemented, all clusters provide two main benefits: scalability and high availability (HA).
Scalability
Scalability refers to an application's ability to support increasing numbers of users. Clusters allow you to provide extra capacity by adding extra servers, thus ensuring scalability.
High availability
HA can be summed up in one word: redundancy. A cluster uses many machines to service requests. Therefore, if any machine in a cluster fails, another machine can transparently take over.
A cluster only provides HA at the application server tier. For a Web system to exhibit true HA, it must be like Noah's ark in containing at least two of everything, including Web servers, gateway routers, switching infrastructures, and so on. (For more on HA, see the HA Checklist.)
Cluster types
J2EE clusters usually come in two flavors: shared nothing and shared disk. In a shared-nothing cluster, each application server has its own filesystems with its own copy of applications running in the cluster. Application updates and enhancements require updates in every node in the cluster. With this setup, large clusters become maintenance nightmares when code pushes and updates are released.
In contrast, a shared-disk cluster employs a single storage device that all application servers use to obtain the applications running in the cluster. Updates and enhancements occur in a single filesystem and all machines in the cluster can access the changes. Until recently, a downside to this approach was its single point of failure. However, SAN gives a single logical interface into a redundant storage medium to provide failover, failback, and scalability. (For more on SAN, see the Storage Infrastructure sidebar.)
When comparing J2EE application servers' cluster implementations, it's important to consider:
- Cluster implementation
- Cluster and component failover services
- HttpSession failover
- Single points of failure in a cluster topology
- Flexible topology layout
- Maintenance
Cluster implementation
J2EE application servers implement clustering around their implementation of JNDI (Java Naming and Directory Interface). Although JNDI is the core service J2EE applications rely on, it is difficult to implement in a cluster because it cannot bind multiple objects to a single name. Three general clustering methods exist in relation to each application server's JNDI implementation:
- Independent
- Centralized
- Shared global
HP Bluestone Total-e-Server and SilverStream Application Server utilize an independent JNDI tree for each application server. Member servers in an independent JNDI tree cluster do not know or care about the existence of other servers in the cluster. Therefore, failover is either not supported or provided through intermediary services that redirect HTTP or EJB requests. These intermediary services are configured to know where each component in the cluster resides and how to get to an alternate component in case of failure.
One advantage of the independent JNDI tree cluster: shorter cluster convergence and ease of scaling. Cluster convergence measures the time it takes for the cluster to become fully aware of all the machines in the cluster and their associated objects. However, convergence is not an issue in an independent JNDI tree cluster because the cluster achieves convergence as soon as two machines start up. Another advantage of the independent JNDI tree cluster: scaling requires only the addition of extra servers.
However, several weaknesses exist. First, failover is usually the developer's responsibility. That is, because each application server's JNDI tree is independent, the remote proxies retrieved through JNDI are pinned to the server on which the lookup occurred. Under this scenario, if a method call to an EJB fails, the developer has to write extra code to connect to a dispatcher, obtain the address of another active server, do another JNDI lookup, and call the failed method again. Bluestone implements a more complicated form of the independent JNDI tree by making every request go through an EJB proxy service or Proxy LBB (Load Balance Broker). The EJB proxy service ensures that each EJB request goes to an active UBS instance. This scheme adds extra latency to each request but allows automatic failover in between method calls.
Centralized JNDI tree
Sybase Enterprise Application Server implements a centralized JNDI tree cluster. Under this setup, centralized JNDI tree clusters utilize CORBA's CosNaming service for JNDI. Name servers house the centralized JNDI tree for the cluster and keep track of which servers are up. Upon startup, every server in the cluster binds its objects into its JNDI tree as well as all of the name servers.
Getting a reference to an EJB in a centralized JNDI tree cluster is a two-step process. First, the client looks up a home object from a name server, which returns an interoperable object reference (IOR). An IOR points to several active machines in the cluster that have the home object. Second, the client picks the first server location in the IOR and obtains the home and remote. If there is a failure in between EJB method invocation, the CORBA stub implements logic to retrieve another home or remote from an alternate server listed in the IOR returned from the name server.
The name servers themselves demonstrate a weakness of the centralized JNDI tree cluster. Specifically, if you have a cluster of 50 machines, of which five are name servers, the cluster becomes useless if all five name servers go down. Indeed, the other 45 machines could be up and running but the cluster will not serve a single EJB client while the naming servers are down.
Another problem arises from bringing an additional name server online in the event of a total failure of the cluster's original name servers. In this case, a new centralized name server requires every active machine in the cluster to bind its objects into the new name server's JNDI tree. Although it is possible to start receiving requests while the binding process takes place, this is not recommended, as the binding process prolongs the cluster's recovery time. Furthermore, every JNDI lookup from an application or applet really represents two network calls. The first call retrieves the IOR for an object from the name server, while the second retrieves the object the client wants from a server specified in the IOR.
Finally, centralized JNDI tree clusters suffer from an increased time to convergence as the cluster grows in size. That is, as you scale your cluster, you must add more name servers. Keep in mind that the generally accepted ratio of name server machines to total cluster machines is 1:10, with a minimum number of two name servers. Therefore, if you have a 10-machine cluster with two name servers, the total number of binds between a server and name server is 20. In a 40-machine cluster with four name servers, there will be 160 binds. Each bind represents a process wherein a member server binds all of its objects into the JNDI tree of a name server. With that in mind, the centralized JNDI tree cluster has the worst convergence time among all of the JNDI cluster implementations.
Shared global JNDI tree
Finally, BEA WebLogic implements a shared global JNDI tree. With this approach, when a server in the cluster starts up it announces its existence and JNDI tree to the other servers in the cluster through IP (Internet Protocol) multicast. Each clustered machine binds its objects into the shared global JNDI tree as well as its own local JNDI tree.
Having a global and local JNDI tree within each member server allows the generated home and remote stubs to failover and provides quick in-process JNDI lookups. The shared global JNDI tree is shared among all machines within the cluster, allowing any member machine to know the exact location of all objects within the cluster. If an object is available at more than one server in the cluster, a special home object is bound into the shared global JNDI tree. This special home knows the location of all EJB objects with which it is associated and generates remote objects that also know the location of all EJB objects with which it is associated.
The shared global approach's major downsides: the large initial network traffic generated when the servers start up and the cluster's lengthy convergence time. In contrast, in an independent JNDI tree cluster, convergence proves not to be an issue because no JNDI information sharing occurs. However, a shared global or centralized cluster requires time for all of the cluster's machines to build the shared global or centralized JNDI tree. Indeed, because shared global clusters use multicast to transfer JNDI information, the time required to build the shared global JNDI tree is linear in relation to the number of subsequent servers added.
The main benefits of shared global compared with centralized JNDI tree clusters center on ease of scaling and higher availability. With shared global, you don't have to fiddle with the CPUs and RAM on a dedicated name server or tune the number of name servers in the cluster. Rather, to scale the application, just add more machines. Moreover, if any machine in the cluster goes down, the cluster will continue to function properly. Finally, each remote lookup requires a single network call compared with the two network calls required in the centralized JNDI tree cluster.
All of this should be taken with a grain of salt because JSPs, servlets, EJBs, and JavaBeans running on the application server can take advantage of being co-located in the EJB server. They will always use an in-process JNDI lookup. Keep in mind that if you run only server-side applications, little difference exists among the independent, centralized, or shared global cluster implementations. Indeed, every HTTP request will end up at an application server that will do an in-process JNDI lookup to return any object used within your server-side application.
Next, we turn our attention to the second important J2EE application server consideration: cluster and failover services.
Cluster and failover services
Providing J2EE services on a single machine is trivial compared with providing the same services across a cluster. Due to the complications of clustering, every application server implements clustered components in unique ways. You should understand how vendors implement clustering and failover of entity beans, stateless session beans, stateful session beans, and JMS. Many vendors claim to support clustered components but their definitions of what that means usually involve components running in a cluster. For example, BEA WebLogic Server 5.1 supported clustered stateful session beans but if the server that the bean instance was on were to fail, all of the state would be lost. The client would then have to re-create and repopulate the stateful session bean, making it useless in a cluster. It wasn't until BEA WebLogic 6.0 that stateful session beans employed in-memory replication for failover and clustering.
All application servers support EJB clustering but vary greatly in their support of configurable automatic failover. Indeed, some application servers do not support automatic failover in any circumstance by EJB clients. For example, Sybase Enterprise Application Server supports stateful session bean failover if you load the bean's state from a database or serialization. As mentioned above, BEA WebLogic 6.0 supports stateful session bean failover through in-memory replication of stateful session bean state. Most application servers can have JMS running in a cluster but don't have load balancing or failover of individually named Topics and Queues. With that in mind, you'll probably need to purchase a clusterable implementation of JMS such as SonicMQ to get load balancing to Topics and Queues.
Another important consideration, to which we now turn our attention: HttpSession failover.
HttpSession failover
HttpSession failover allows a client to seamlessly get session information from another server in the cluster when the original server on which the client established a session fails. BEA WebLogic Server implements in-memory replication of session information, while HP Bluestone Total-e-Server utilizes a centralized session server with a backup for HA. SilverStream Application Server and Sybase Enterprise Application Server utilize a centralized database or filesystem that all application servers would read and write to.
The main drawback of database/filesystem session persistence centers around limited scalability when storing large or numerous objects in the HttpSession. Every time a user adds an object to the HttpSession, all of the objects in the session are serialized and written to a database or shared filesystem. Most application servers that utilize database session persistence advocate minimal use of the HttpSession to store objects, but this limits your Web application's architecture and design, especially if you are using the HttpSession to store cached user data.
Memory-based session persistence stores session information in-memory to a backup server. Two variations of this method exist. The first method writes HttpSession information to a centralized state server. All machines in the cluster write their HttpSession objects to this server. In the second method, each cluster node chooses an arbitrary backup node to store session information in-memory. Each time a user adds an object to the HttpSession, that object alone is serialized and added in-memory to a backup server.
Under these methods, if the number of servers in the cluster is low, the dedicated state server proves better than in-memory replication to an arbitrary backup server because it frees up CPU cycles for transaction processing and dynamic page generation.
On the other hand, when the number of machines in the cluster is large, the dedicated state server becomes the bottleneck and in-memory replication to an arbitrary backup server (versus a dedicated state server) will scale linearly as you add more servers. In addition, as you add more machines to the cluster you will need to constantly tune the state server by adding more RAM and CPUs. With in-memory replication to an arbitrary backup server, you just add more machines and the sessions evenly distribute themselves across all machines in the cluster. Memory-based persistence provides flexible Web application design, scalability, and high availability.
Now that we've tackled HttpSession failover, we will examine single points of failure.
Single points of failure
Cluster services without backup are known as single points of failure. They can cause the whole cluster or parts of your application to fail. For example, WebLogic JMS can have only a Topic running on a single machine within the cluster. If that machine happens to go down and your application relies on JMS Topics, your cluster will be down until another WebLogic instance is started with that JMS Topic. (Note that only durable messages will be delivered when the new instance is started.)
Ask yourself if your cluster has any single points of failure. If it does, you will need to gauge whether or not you can live with them based on your application requirements.
Next up, flexible scaling topologies.
Flexible scaling topologies
Clustering also requires a flexible layout of scaling topologies. Most application servers can take on the responsibilities of an HTTP server as well as those of an application server, as seen in Figure 1.
The architecture illustrated in Figure 1 is good if most of your Website serves dynamic content. However, if your site serves mostly static content, then scaling the site would be an expensive proposition, as you would have to add more application servers to serve static HTML page requests. With that in mind, to scale the static portions of your Website, add Web servers; to scale the dynamic portions of your site, add application servers, as in Figure 2.
The main drawback of the architecture shown in Figure 2: added latency for dynamic pages requests. However, it provides a flexible methodology for scaling static and dynamic portions of the site independently.
Finally, what application server discussion would be complete without a look at maintenance?
Maintenance
With a large number of machines in a cluster, maintenance revolves around keeping the cluster running and pushing out application changes. Application servers should provide agents to sense when critical services fail and then restart them or activate them on a backup server. Further, as changes and updates occur, an application server should provide an easy way to update and synchronize all servers in the cluster.
Sybase Enterprise Application Server and HP Bluestone Total-e-Server provide file and configuration synchronization services for clusters. Sybase Enterprise Application Server provides file and configuration synchronization services at the host, group, or cluster level. Bluestone offers file and configuration synchronization services only at the host level. If large applications as well as numerous changes need to be deployed, this process will take a long time. BEA WebLogic Server provides configuration synchronization only. Of the two, configuration synchronization with a storage area network works better because changes can be made to a single logical storage medium and all of the machines in the cluster will receive the application file changes. Each machine then only has to receive configuration changes from a centralized configuration server. SilverStream Application server loads application files and configuration from a database using dynamic class loaders. The dynamic class loaders facilitate application changes in a running application server.
That concludes our look at the important features to consider in application servers. Next let's look at how our four popular application servers handle themselves in relation to our criteria.
Application server comparisons
Now that we have talked about clusters in general, let's focus our attention upon individual application servers and apply what we learned to the real world. Below, you'll find comparisons of:
- HP Bluestone Total-e-Server 7.2.1
- Sybase Enterprise Application Server 3.6
- SilverStream Application Server 3.7
- BEA WebLogic Server 6.0
Each application server section provides a picture of an HA architecture followed by a summary of important features as presented in this article.
HP Bluestone Total-e-Server 7.2.1
General cluster summary:
Bluestone implements independent JNDI tree clustering. An LBB, which runs as a plug-in within a Web server, provides load balancing and failover of HTTP requests. LBBs know which applications are running on which UBS (universal business server) instance and can direct traffic appropriately. Failover of stateful and stateless session and entity beans is supported in between method calls through EJB Proxy Service and Proxy LBB. The main disadvantages of EJB Proxy Service are that it adds extra latency to each EJB request and it runs on the same machine as the UBS instances. The EJB Proxy Service and UBS stubs allow failover in case of UBS instance failure but do not allow failover in case of hardware failure. Hardware failover is supported through client-side configuration of apserver.txt or Proxy LBB configuration of apserver.txt. The client-side apserver.txt lists all of the components in the cluster. When additional components are added to the cluster, all clients need to be updated through the BAM (Bluestone Application Manager) or manually on a host-by-host basis. Configuring apserver.txt on the Proxy LBB insulates clients from changes in the cluster but again adds additional latency to each EJB call. HP Bluestone is the only application server to provide clustered and load-balanced JMS.
Cluster convergence time:
Least, when compared with centralized and shared global JNDI tree clusters.
HttpSession failover:
In-memory centralized state server and backup state server or database.
Single points of failure:
None.
Flexible cluster topology:
All clustering topologies are supported.
Maintenance:
Bluestone excels at maintenance. Bluestone provides a dynamic application launcher (DAL) that the LBB calls when an application or machine is down. The DAL can restart applications on the primary or backup machine. In addition, Bluestone provides a configuration and deployment tool called Bluestone Application Manager (BAM), which can deploy application packages and their associated configuration files. The single downside of this tool is that you can configure only one host at a time -- problematic for large clusters.
Sybase Enterprise Application Server 3.6
General cluster summary:
Enterprise Application Server implements centralized JNDI tree clustering, and a hardware load balancer provides load balancing and failover of HTTP requests. The two name servers per cluster can handle HTTP requests, but for performance considerations they typically should be dedicated exclusively to handling JNDI requests.
Enterprise Application Server 3.6 does not have Web server plug-ins; they will, however, be available with the EBF (Error and Bug Fixes) for 3.6.1 in February. The application supports stateful and stateless session and entity bean failover in between method calls. Keep in mind that Enterprise Application Server does not provide any monitoring agents or dynamic application launchers, requiring you to buy a third-party solution like Veritas Cluster Server for the single points of failure or automatic server restarts. Enterprise Application Server does not support JMS.
Cluster convergence time:
Convergence time depends on the number of name servers and member servers in the cluster. Of the three cluster implementations, centralized JNDI tree clusters produce the worst convergence times. Although convergence time is important, member machines can start receiving requests after binding objects into a name server that is utilized by an EJB client (this is not recommended, however).
HttpSession failover:
HttpSession failover occurs through a centralized database. There's no option for in-memory replication.
Single points of failure:
No single points of failure exist if running multiple name servers.
Flexible cluster topology:
A flexible cluster topology is limited due to the lack of Web server plug-ins.
Maintenance:
Sybase provides the best option for application deployment through a file and configuration synchronization. It can synchronize clusters at the component, package, servlet, application, or Web application level. You can also choose to synchronize a cluster, group of machines, or individual host -- an awesome feature but it can take a while if there are many machines in the cluster and many files to add or update. A weakness is the lack of dynamic application launching services, which means you must purchase a third-party solution such as Veritas Cluster Server.
SilverStream Application Server 3.7
General cluster summary:
When setting up a SilverStream cluster, choose from two configurations: dispatcher-based or Web server integration-module (WSI)-based. In a dispatcher-based cluster, a user connects to the dispatcher or hardware-based dispatcher -- Alteon 180e, for example. Then the dispatcher sends an HTTP redirect to pin the client to a machine in the cluster. From that point on, the client is physically bound to a single server. In the dispatcher configuration there is no difference between a single machine and cluster because, as far as the client is concerned, the cluster becomes a single machine. The major disadvantage: you can't scale the static portions of the site independently of the dynamic portions.
In a WSI-based cluster, a user connects to a dispatcher, which load balances and failovers HTTP requests to Web servers. Each Web server has a plug-in that points to a load balancer fronting a SilverStream cluster. The WSI cluster does not use redirection, so every HTTP request is load balanced across any of the Web servers. The secondary load balancer insures failover at the application server tier. A WSI architecture advantage over the dispatcher architecture: the ability to independently scale static and dynamic portions of a site. In a major disadvantage, the ArgoPersistenceManager is required for HttpSession failover. In either architecture, EJB clients still cannot failover in between method calls. EJB failover totally remains the developer's responsibility. Finally, SilverStream does not support clustered JMS.
HttpSession failover:
SilverStream provides HttpSession failover by a centralized database and the ArgoPersistenceManager. The solution, unfortunately, is proprietary. Instead of using the standard HttpSession to store session information to a database, you must use the product's ArgoPersistenceManager class -- a drawback.
Cluster convergence time:
Least, when compared with centralized and shared global JNDI tree clusters.
Single points of failure:
None with the above architectures.
Flexible cluster topology:
All clustering topologies supported.
Maintenance:
Cache manager and dynamic class-loaders provide an easy way to deploy and upgrade running applications with little interruption to active clients. When an application is updated on one server in the cluster, the update gets written to a database and the cache manager invalidates the caches on all other servers, forcing them to refetch the updated parts of the application on next access. The only downside of this approach is the time needed to load applications out of the database and into active memory during the initial access.
BEA WebLogic Server 6.0
General cluster summary:
WebLogic Server implements clustering through a shared global JNDI cluster tree. Under this setup, when an individual server starts up it puts its JNDI tree into the shared global JNDI tree. The server then uses its copy of the tree to service requests, allowing an individual server to know the exact location of all objects in the cluster. Stubs that clients utilize are cluster-aware, meaning that they are optimized to work on their server of origin but also possess knowledge of all other replica objects running in different application servers. Because clusterable stubs have knowledge of all replica objects in the cluster, they can transparently failover to other replica objects in the cluster. A unique feature of WebLogic Server is in-memory replication of stateful session beans as well as configurable automatic failover of EJB remote objects. WebLogic defines clusterable as a service that can run in a cluster. JMS is clusterable but each Topic or Queue only runs on a single server within the cluster. You cannot load balance or failover JMS Topics or Queues in a cluster -- a major weakness of WebLogic's JMS implementation.
HttpSession failover:
WebLogic Server provides HttpSession failover by transparent in-memory state replication to an arbitrary backup server or database server. Every machine in the cluster picks a different backup machine. If the primary server fails, the backup becomes a primary and the primary picks a new backup server. A unique feature of WebLogic is cookie independence. Both HP Bluestone and Enterprise Application Server require cookies for HttpSession failover. WebLogic can use encrypted information in the URL to direct a client to the backup server if there is a failure.
Single points of failure:
JMS and Administration server.
Flexible cluster topology:
All clustering topologies supported.
Maintenance:
WebLogic's weakness is maintenance. Although BEA has made positive steps with configuration synchronization, WebLogic Server does not provide any monitoring agents, dynamic application launchers, or file synchronization services. This shortfall requires you to buy a third-party solution for the single points of failure or implement sneaker HA. With sneaker HA, all WebLogic Administrators have to wear Nike Air Streak Vapor IV racing shoes. If a server goes down they must sprint to the machine and troubleshoot the problem. However, if you employ SAN you don't need file synchronization services, but most developers are just beginning to realize the benefits of SAN.
Analysis
Overall BEA WebLogic Server 6.0 has the most robust and well thought-out clustering implementation. HP Bluestone Total-e-Server 2.7.1, Sybase Enterprise Application Server 3.6, and SilverStream Application Server 3.7 would be the next choices, in that order.
Picking the right application server entails making tradeoffs. If you are writing an application where you will have EJB clients (applets and applications), Web clients, extensive use of HttpSession (for caching), and ease of scaling and failover, you will want to go with BEA WebLogic 6.0. If your application requires heavy use of JMS and most of your clients are Web clients, Bluestone will probably be a better choice. From a clustering standpoint Sybase Enterprise Application Server 3.7 lacks important clustering features such as JMS, in-memory HttpSession replication, session-based server affinity, and partitioning through Web server plug-ins. Sybase Enterprise Application Server 3.7 does, however, bring to the table file and configuration synchronization services. But this benefit is minimized if you are using SAN. SilverStream Application Server has the weakest implementation of clustering and lacks clustered JMS, in-memory HttpSession replication, and failover.
Conclusion
In this article you have gained a foundational understanding of clustering, clustering methods, and important cluster services. We have examined the benefits and drawbacks of each application server and discussed the important cluster-related features to look for in an application server. With this knowledge, you now understand how to set up clusters for high availability and scalability. However, this represents just the beginning of your journey. Go out, get some evaluation clustering licenses, and Control-C some application servers.
In Part 2, we will start writing code, test the application server vendors' claims, and provide failover and cluster strategies for each of the different application servers. Further, we will use the J2EE Java Pet Store for load testing and cluster convergence benchmarks.
Part 2
Within the J2EE framework, clusters provide an infrastructure for high availability (HA) and scalability. A cluster is a group of application servers that transparently run your J2EE application as if the group were a single entity. However, Web applications behave differently when they are clustered as they must share application objects with other cluster members through serialization. Moreover, you'll have to contend with the extra configuration and setup time.
To avoid major Web application rework and redesign, you should from the very beginning of your development process consider cluster-related programming issues, as well as critical setup and configuration decisions in order to support intelligent load balancing and failover. Finally, you will need to have a management strategy to handle failures.
Read the whole "J2EE clustering" series:
- Part 1: Clustering technology is crucial to good Website design; do you know the basics?
- Part 2: Migrate your application from a single machine to a cluster, the easy way
Building on the information in Part 1, I'll impart an applied understanding of clustering. Further, I'll examine clustering-related issues and their possible solutions, as well as the advantages and disadvantages of each choice. I'll also demonstrate programming guidelines for clustering. Finally, I'll show you how to prepare for outages. (Note that, due to licensing constraints, this article will not cover benchmarking.)
Set up your cluster
During cluster setup, you need to make important decisions. First, you have to choose a load balancing method. Second, you must decide how to support server affinity. Finally, you need to determine how you will deploy the server instances among clustered nodes.
Load balancing
You can choose between two generally recognized options for load balancing a cluster: DNS (Domain Name Service) round robin or hardware load balancers.
DNS round robin
DNS is the process by which a logical name (i.e., www.javaworld.com) is converted to an IP address. In DNS round-robin load balancing, a single logical name can return any IP address of the machines in a cluster.
DNS round-robin load balancing's advantages include:
- Cheap and easy setup
- Simplicity
- No server affinity support. When a user receives an IP address, it is cached on the browser. Once the cache expires, the user makes another request for the IP address associated with a logical name. That second request can return the IP address of any other machine in the cluster, resulting in a lost session.
- No HA support. Imagine a cluster of n servers. If one of those servers goes down, every nth request to the DNS server will go to the dead server.
- Changes to the cluster take time to propagate to the rest of the Internet. Many corporations' and ISPs' DNS servers cache DNS lookups from their clients. Even if your DNS list of servers in the cluster could change dynamically, it would take time for the cached entries on other DNS servers to expire. For example, after a downed server is removed from your cluster's DNS list, AOL clients could still attempt to hit the downed server if AOL's DNS servers cached entries to the downed server. As a result, AOL users would not be able connect to your site even if other machines in the cluster were available.
- No guarantee of equal client distribution across all servers in the cluster. If you don't configure cooperating DNS servers to support DNS load balancing, they could take only the first IP address returned from the initial lookup and use that for their client requests. Imagine a partner corporation with thousands of employees all pinned to a single server in your cluster!
Hardware load balancers
In contrast, a hardware load balancer (like F5's Big IP) solves most of these problems through virtual IP addressing. A load balancer presents to the world a single IP address for the cluster. The load balancer receives each request and rewrites headers to point to other machines in the cluster. If you remove any machine in the cluster, the changes take effect immediately.
Hardware load balancers' advantages include:
- Server affinity when you're not using SSL
- HA services (failover, monitoring, and so on)
- Metrics (active sessions, response time, and so on)
- Guaranteed equal client distribution across cluster
However, hardware load balancers exhibit disadvantages:
- High cost -- 0,000 to 0,000, depending on features
- Complex setup and configuration
Once you have picked your load balancing scheme, you must decide how your cluster will support server affinity.
Server affinity
Server affinity becomes a problem when using SSL without Web server proxies. (Server affinity directs a user to a particular server in the cluster for the duration of her session.) Hardware load balancers rely on cookies or URL readings to determine where requests are directed. If requests are SSL encrypted, hardware load balancers cannot read the header, cookie, or URL information. To solve the problem, you have two choices: Web server proxies or SSL accelerators.
Web server proxies
In this scenario, a hardware load balancer acts like a DNS load balancer for the Web server proxies, except that it acts through a single IP address. The Web servers decrypt SSL requests and pass them to the Web server plug-in (Web server proxy). Once the plug-in receives a decrypted request, it can parse the cookie or URL information and redirect the request to the application server where the user's session state resides.
With Web server proxies, the major advantages include:
- Server affinity with SSL
- No additional hardware required (only the hardware load balancer is needed)
The disadvantages are:
- The hardware load balancer cannot use metrics to direct requests
- Extensive SSL use puts an additional strain on the Web servers
- Web server proxies need to support server affinity
SSL accelerators
SSL accelerator networking hardware processes SSL requests to the cluster. It sits in front of the hardware load balancer, allowing the hardware load balancer to read decrypted information in cookies, headers, and URLs. The hardware load balancer can then use its own metrics to direct requests. With this setup, you can avoid Web proxies if you choose and still achieve server affinity through SSL.
With SSL accelerators, you benefit from:
- A flexible topology layout (with Web proxies or without) that supports server affinity and SSL
- Off-loaded SSL processing to the SSL accelerator, which increases scalability
- Centralized SSL certificate management in a single box
The disadvantages comprise:
- A high cost when you buy two accelerators to achieve HA
- Added setup and configuration complexity
Application server distribution
When distributing application server instances throughout your cluster, you must decide whether or not you want multiple application server instances on single nodes in the cluster, and determine the total number of nodes in your cluster.
The number of application server instances on a single node depends on the number of CPUs on the box, CPU utilization, and available memory. Consider multiple instances on a single box in any of three situations:
- You have three or more CPUs not fully saturated under load
- The instance heap size is set too large, causing garbage collection times to increase
- The application is not I/O bound
Determining the optimal number of nodes in your cluster is an iterative process. First, profile and optimize the application. Second, use load-testing software to simulate your expected peak usage. Finally, add additional surplus nodes to handle the load when failures occur.
Ideally, it would be best to push out development releases to a staging cluster to catch clustering issues as they occur. Unfortunately, developers create most applications for a single machine, then migrate them to a clustered environment, a situation that can break the application.
Session-storage guidelines
To minimize the breakage, follow these general guidelines for application servers that use in-memory or database session persistence:
- Make sure all objects and those they reference recursively in the HttpSession are serializable. As a rule of thumb, all objects should implement java.io.Serializable as a part of their canonical form.
- Whenever you change an object's state in the HttpSession, call session.setAttribute(...) to flag the object as changed and save the changes to a backup server or database:
AccountModel am = (AccountModel)session.getAttribute("account");
//You need this so the AccountModel object on the backup receives the
//Credit card
session.setAttribute("account",am);
- The ServletContext is not serializable, so do not use it as an instance variable (unless it is marked as transient) for any object directly or indirectly stored within the HttpSession. Getting a reference to the
- ServletContext proves easier in a Servlet 2.3 container when the HttpSessionBindingEvent holds a reference to the ServletContext.
- EJB remotes may not be serializable. When they are not serializable, you need to override the default serialization mechanism as follows (this class does not implement java.io.Serializable because AccountModel, its superclass, does):
... public class AccountWebImpl extends AccountModel implements ModelUpdateListener, HttpSessionBindingListener {
transient private Account acctEjb;
...
private void writeObject(ObjectOutputStream s) {
try {
s.defaultWriteObject(); Handle acctHandle = acctEjb.getHandle();
s.writeObject(acctHandle);
}
catch (IOException ioe) {
Debug.print(ioe);
throw new GeneralFailureException(ioe);
}
catch (RemoteException re) {
throw new GeneralFailureException(re);
}
}
private void readObject(ObjectInputStream s) {
try {
s.defaultReadObject();
Handle acctHandle = (Handle)s.readObject()
Object ref = acctHandle.getEJBObject();
acctEjb = (Account) PortableRemoteObject.narrow(ref,Account.class);
}
catch (ClassNotFoundException cnfe) {
throw new GeneralFailureException(cnfe);
}
catch (RemoteException re) {
throw new GeneralFailureException(re);
}
catch (IOException ioe) {
Debug.print(ioe);
throw new GeneralFailureException(ioe);
}
}
- HttpSessionBindingListener's valueBound(HttpSessionBindingEvent event) method is called after the session is restored from disk and after every call to HttpSession's setAttribute(...) method. valueBound(HttpSessionBindingEvent event), however, is not called during failover.
In-memory session ststate replication
In-memory session state replication proves more complicated than database persistence because individual objects in the HttpSession are serialized to a backup server as they change. With database session persistence, the objects in the session are serialized together when any one of them changes. As a side effect, in-memory session state replication clones all HttpSession objects stored directly under a session key. This has virtually no effect if each object stored under a session key is independent of the other objects stored under different session keys. However, if the objects stored under session keys are highly dependent on other objects within the HttpSession, copies will be made on the backup machine. After failing over, your application will continue to run but some features may not work -- a shopping cart may refuse to accept more items, for instance. The problem stems from different parts (updating the shopping cart and displaying the shopping cart) of your application referring to their own copies of the shopping cart object. The class responsible for updating the cart is making changes to its copy of the shopping cart while the JSPs attempt to display their copy of the shopping cart. In a single-server environment, this problem would not arise because both parts of your application would point to the same shopping cart.
Here is an example of indirectly copying objects:
import java.io.*;
public class Aaa implements Serializable {
String name;
pubic void setName (String name) {
this.name = name;
}
public String getName( ) {
return name;
}
}
import java.io.*;
public class Bbb implements Serializable {
Aaa a;
public Bbb (Aaa a) {
this.a = a;
}
pubic void setName (String name) {
a.setName(name);
}
public String getName( ) {
return a.getName();
}
}
In first.jsp on server1:
<%
Aaa a = new Aaa();
a.setName("Abe");
Bbb b = new Bbb(a);
// a is copied to backup machine under key "a"
session.setAttribute("a",a);
// b is copied to backup machine under key "b"
session.setAttribute("b",b);
%>
In second.jsp on server1:
<%
Bbb b = (Bbb)session.getAttribute("b");
b.setName("Bob");
// b is copied to backup machine under key "b"
// but object Aaa under key "a" has the name "Abe"
// and "b"'s Aaa has the name "Bob"
session.setAttribute("b",b);
---> Failure trying to get to server1's third.jsp
----->Failover to server2's (backup machine) third.jsp
In third.jsp on server2:
The name associated with Object Aaa is:
<%=((Aaa)session.getAttribute("a")).getName()%>
The name associated with Object Aaa through Object Bbb is:
<%=((Bbb)session.getAttribute("b")).getName()%>
...
//End of third.jsp
The first expression tag outputs "Abe", while the second expression tag outputs "Bob". On a single server, both expressions would output "Bob".
To see invalid session state copies, create a Cluster Object Relationship Diagram (CORD) like the figure below.
JavaPetStore CORD. Click on thumbnail to view full-size image.
In the diagram, the ovals represent objects directly stored under a key value in the HttpSession. The squares represent objects indirectly referenced by an object stored under an HttpSession key. The filled-in arrows point to objects that are the source object's instance variables. The open arrows indicate an inheritance relationship.
Counting the number of arrows pointing into an object usually tell you the number of copies of that object will be generated. If the arrow points to an oval, you have to add one to the total number of arrows because the oval is stored in the HttpSession under a session key. For example, look at the ContactInformation oval. It has one arrow pointing into it, indicating two copies: one stored directly under a session key and another stored as an instance variable of AccountWebImpl.
I say usually because complex relationships tend to bend this rule of thumb. Look at ShoppingClientControllerWebImpl; it has one arrow pointing into it, so there are two copies, right? Wrong! There are three copies: one through ModelManager, one through AccountWebImpl, and one through RequestProcessor. You cannot count ShoppingClientControllerWebImpl itself because it is not directly stored under an HttpSession key.
Let's try another example. How many copies of ModelManager are there? If you answered four, you are right. There is a copy from ModelManager itself because it is stored under an HttpSession key, AccountWebImpl, ShoppingCartWebImpl, and RequestProcessor. I didn't count the arrow from RequestToEventTranslator because it is not directly stored under an HttpSession key, and its reference to ModelManager is the same as the reference from RequestProcessor.
Note: With in-memory replication, always remember: any object stored under an HttpSession key will be cloned and sent to the backup machine.
To keep multiple object copies to a minimum, store primitive object types, simple objects, or independent objects under session keys in HttpSession. If you can't avoid having complex interrelated objects in the HttpSession, use session.setAttribute(...) to remove copies once the user has failed over. For example, to replace the clone of ModelManager in AccountWebImpl with the real ModelManager, you need to call session.setAttribute("account",accountWebImplWithRealModelManager). In most cases, you will focus your analysis to copied objects with shared state. If the object doesn't have any shared instance variables, you can leave it alone. The single side effect: increased memory usage for every client that fails over. After testing proves that everything fails over properly in your cluster, you need to develop a cluster management strategy.
A cluster management strategy document defines what can go wrong and how to solve the problems. Generally, there are four categories of problems:
- Hardware
- Software
- Network
- Database
Since this is JavaWorld, I will focus on software. You will probably want to discuss the other issues with your local sysadmin, network admin, and DBA, respectively.
If software on a machine in a cluster fails, other cluster members must assume responsibility for the downed server, a process known as failover. In JSP applications, failover occurs at the Web proxy or hardware load balancer. For example, a request comes into the Web proxy, which notices the server it is trying to reach is down, so it sends the request to another application server. This application server activates the users' backup session state and fulfills the request. In an EJB client application, the remote references try different servers in the cluster until they receive a response.
This description makes failover seem trivial, but we have covered only the best-case scenario in which a failure occurs between requests. Failover proves more difficult when a failure occurs during a request. Let's take a look at examples involving JSPs and EJBs.
For our JSP example, imagine a user placing an order on your Website. When the user clicks the Submit button, the page seems to hang, and then he receives a message that reads "Response contained no data." In this situation, one of two things could have happened. The order may have completed but the server failed before delivering the response page. On the other hand, the server may have failed before saving the order and sending the response. Does the proxy automatically call the same URL on another server and reinitiate the transaction, causing possible duplicates? Or does it return an error and force the user to contact a member of your support team?
In our EJB example, imagine a user modifying inventory on a standalone Java application. Once the user clicks the Save button, a request reaches an EJB, but the application returns a RemoteException. Again, one of two things could have happened. The inventory could have been saved, but the server may have failed before delivering a reply. Or, the server could have failed before making inventory changes. Should the EJB remote automatically reattempt the same remote call on another server in the cluster and risk duplicates or inconsistent data?
After trying different failover techniques, I concluded that responsibility for transparent failover rests with the application server. You can try to use transaction tables or transaction identifiers in cookies, but the pain-to-gain ratio doesn't justify either. The simplest solution: after a server failure, run a set of stored procedures that find inconsistencies within the database and notify the interested parties.
Wrap it all up
This article has given you an applied understanding of clustering. You've learned how to set up, program for, and maintain J2EE clusters. You've seen the issues related to clustering, as well as possible solutions. With this practical knowledge, you can set up a working J2EE cluster.
But your work is not done: you have to develop the network, hardware, and database infrastructure to ensure HA. The easiest way to develop these services is through an enterprise hosting service. Most enterprise hosting services will set up your redundant networking, database, and hardware services. You just provide the clusterable code. Good luck and happy clustering.
Source: http://www.javaworld.com/jw-02-2001/jw-0223-extremescale.html?page=1#
http://www.javaworld.com/jw-08-2001/jw-0803-extremescale2.html?page=1
Non-Functional Requirements - Minimal Checklist
All IT systems at some point in their lifecycle need to consider non-functional requirements and their testing. For some projects these requirements warrant extensive work and for other project domains a quick check through may be sufficient. As a minimum, the following list can be a helpful reminder to ensure you have covered the basics. Based on your own project characteristics, I would recommend the topics are converted into SMART (Specific, Measurable, Attainable, Realisable, Timeboxed / Traceable) requirements with the detail and rigour appropriate to your project.
The list is also available at the bottom of the article as a one-page PDF document. While it is easy to make the list longer by adding more items, I would really like to hear how to make the list better while keeping it on one page (and readable) to share with other visitors here.
Security
• Login requirements - access levels, CRUD levels
• Password requirements - length, special characters, expiry, recycling policies
• Inactivity timeouts – durations, actions
Audit
• Audited elements – what business elements will be audited?
• Audited fields – which data fields will be audited?
• Audit file characteristics - before image, after image, user and time stamp, etc
Performance
• Response times - application loading, screen open and refresh times, etc
• Processing times – functions, calculations, imports, exports
• Query and Reporting times – initial loads and subsequent loads
Capacity
• Throughput – how many transactions per hour does the system need to be able to handle?
• Storage – how much data does the system need to be able to store?
• Year-on-year growth requirements
Availability
• Hours of operation – when is it available? Consider weekends, holidays, maintenance times, etc
• Locations of operation – where should it be available from, what are the connection requirements?
Reliability
• Mean Time Between Failures – What is the acceptable threshold for down-time? e.g. one a year, 4,000 hours
• Mean Time To Recovery – if broken, how much time is available to get the system back up again?
Integrity
• Fault trapping (I/O) – how to handle electronic interface failures, etc
• Bad data trapping - data imports, flag-and-continue or stop the import policies, etc
• Data integrity – referential integrity in database tables and interfaces
• Image compression and decompression standards
Recovery
• Recovery process – how do recoveries work, what is the process?
• Recovery time scales – how quickly should a recovery take to perform?
• Backup frequencies – how often is the transaction data, set-up data, and system (code) backed-up?
• Backup generations - what are the requirements for restoring to previous instance(s)?
Compatibility
• Compatibility with shared applications – What other systems does it need to talk to?
• Compatibility with 3rd party applications – What other systems does it have to live with amicably?
• Compatibility on different operating systems – What does it have to be able to run on?
• Compatibility on different platforms – What are the hardware platforms it needs to work on?
Maintainability
• Conformance to architecture standards – What are the standards it needs to conform to or have exclusions from?
• Conformance to design standards – What design standards must be adhered to or exclusions created?
• Conformance to coding standards – What coding standards must be adhered to or exclusions created?
Usability
• Look and feel standards - screen element density, layout and flow, colours, UI metaphors, keyboard shortcuts
• Internationalization / localization requirements – languages, spellings, keyboards, paper sizes, etc
Documentation
• Required documentation items and audiences for each item
Ten advantages of an ORM (Object Relational Mapper)
Here's a list of ten reasons why you should consider an ORM tool. Now not all ORMs are created equal, but these are key features that a first class ORM will handle for you.
1. Facilitates implementing the Domain Model pattern (Thanks Udi). This one reason supercedes all others. In short using this pattern means that you model entities based on real business concepts rather than based on your database structure. ORM tools provide this functionality through mapping between the logical business model and the physical storage model.
2. Huge reduction in code. ORM tools provide a host of services thereby allowing developers to focus on the business logic of the application rather than repetitive CRUD (Create Read Update Delete) logic.
3. Changes to the object model are made in one place. One you update your object definitions, the ORM will automatically use the updated structure for retrievals and updates. There are no SQL Update, Delete and Insert statements strewn throughout different layers of the application that need modification.
4. Rich query capability. ORM tools provide an object oriented query language. This allows application developers to focus on the object model and not to have to be concerned with the database structure or SQL semantics. The ORM tool itself will translate the query language into the appropriate syntax for the database.
5. Navigation. You can navigate object relationships transparently. Related objects are automatically loaded as needed. For example if you load a PO and you want to access it's Customer, you can simply access PO.Customer and the ORM will take care of loading the data for you without any effort on your part.
6. Data loads are completely configurable allowing you to load the data appropriate for each scenario. For example in one scenario you might want to load a list of POs without any of it's child / related objects, while in other scenarious you can specify to load a PO, with all it's child LineItems, etc.
7. Concurrency support. Support for multiple users updating the same data simultaneously.
8. Cache managment. Entities are cached in memory thereby reducing load on the database.
9. Transaction management and Isolation. All object changes occur scoped to a transaction. The entire transaction can either be committed or rolled back. Multiple transactions can be active in memory in the same time, and each transactions changes are isolated form on another.
10. Key Management. Identifiers and surrogate keys are automatically propogated and managed.
source :http://blogs.msdn.com/b/gblock/archive/2006/10/26/ten-advantages-of-an-orm.aspx
